
These are examples of systems consolidated by software.
Domain-Driven GraphQL Schema Design using Event Storming
Last updated Jan 31st, 2020
A GraphQL schema is a declarative, self-documenting, organization-wide API. It's pretty important to spend a little bit of time on getting it right. However, unless you're a domain expert, that can be hard to do. In this article, we'll look at an approach to GraphQL schema design that involves both non-technical domain experts and developers.
Introduction
Designing your GraphQL schema is a potentially expensive task.
It's potentially expensive because if we respect the principles of GraphQL, the (company-wide) GraphQL schema becomes the singular source of truth for our client applications, and the contract for our sever-side data sources.
The single source of truth isn't exactly the type of thing you want to get terribly wrong the first time around.
This sentiment is shared by expert GraphQL-r and developer from Pinterest Engineering, Francesca Guiducci, who says to "involve others when designing the GraphQL schema" (via Netlify, Jan 21st, 2019).
I'm with Francesca on this one. Your GraphQL API is the language others use to build on top of your services, and if it doesn't come from a shared understanding of the domain, some domain concepts could end up being really off.
Designing a GraphQL schema is not usually something a single developer creates in isolation.
Domain-Driven GraphQL?
Domain-Driven GraphQL means putting an effort into understanding the domain you work in, and using that knowledge to drive development against a model of the business that mimics how it works in the real world.
Code that acts as a software representation of the business is more correct, more tolerant to change, has less inaccurate and undesireable side-effects, and can be understood by everyone.
Often, developers are really good at developing, but don't hold a great understanding of the domain. To fix that, we can spend more time interacting with people who do understand the domain.
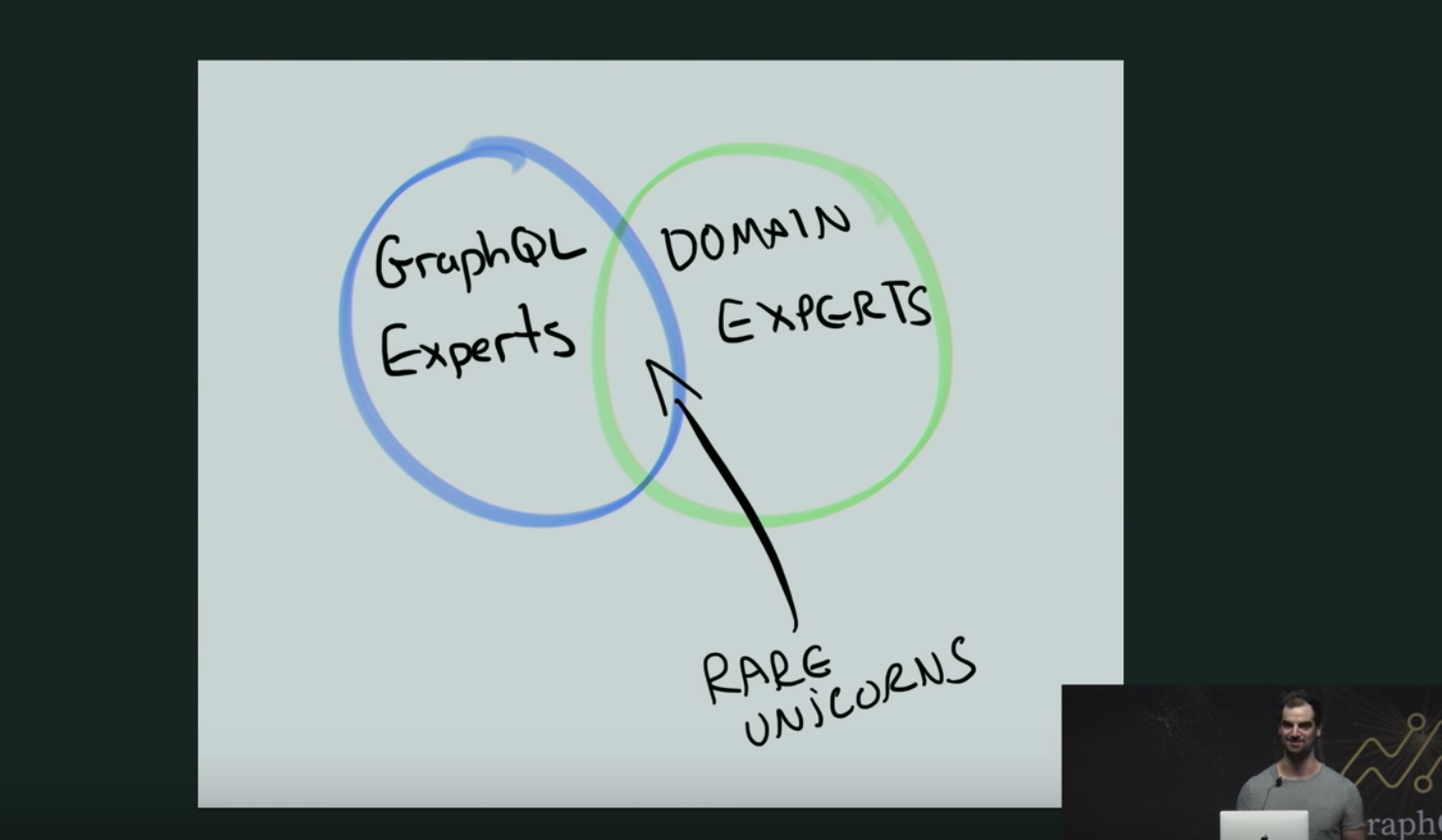
You're probably more likely to find a rare unicorn strolling down your company office than you are to find someone who is both a GraphQL Expert AND a Domain Expert - from Marc-André Giroux's talk at GraphQL Summit 2018.
This post was inspired by a tweet I blasted out recently. It describes how we can stack our odds of success for building an accurate GraphQL schema by involving domain experts in a process called Event Storming.
🖼️Domain-Driven GraphQL Schema Design (in 6 tweets)👇#graphQL #eventstorming #dddesign pic.twitter.com/5P2p0XzI2q
— Khalil Stemmler (@stemmlerjs) January 23, 2020
Let's talk about it.
Event Storming
By definition, Event Storming is:
A group or workshop-based modeling technique that brings stakeholders and developers together in order to understand the domain quickly.

It all started when a developer named Alberto Brandolini found himself short on time to organize a traditional UML use case design session with some clients. Thinking quickly, he improvised with some sticky notes, markers, and a whiteboard- inadvertently creating Event Storming.
Today, Event Storming has become something of a staple in the DDD community.
It's a quick (and fun!) interactive design process that engages both developers and business-folk to learn the business and create a shared understanding of the problem domain.
The result is either:
- a) A big-picture understanding of the domain (less precise but still very useful).
- b) 🔥A design-level understanding (more precise), which yields software artifacts (aggregates, commands, views, domain events) agreed on by both developers and domain experts that can be turned into rich domain layer code.
By running an Event Storming session, we end up answering a lot of questions and have all the pieces needed to construct a rich GraphQL schema.
Using an Event Storm to design a GraphQL Schema
You can use this approach in any context. If you've been asked to build a new app, or you want to start to introduce GraphQL on an existing project, you can take the following approach.
💡Step 1. Domain Events
Plot out all of the events that happen for the main story in your application as past-tense verbs.
For my Hackernews-like app, DDDForum.com, that looks like:
UserCreated => MemberCreated => PostCreated => CommentCreated, CommentUpvoted, etc.
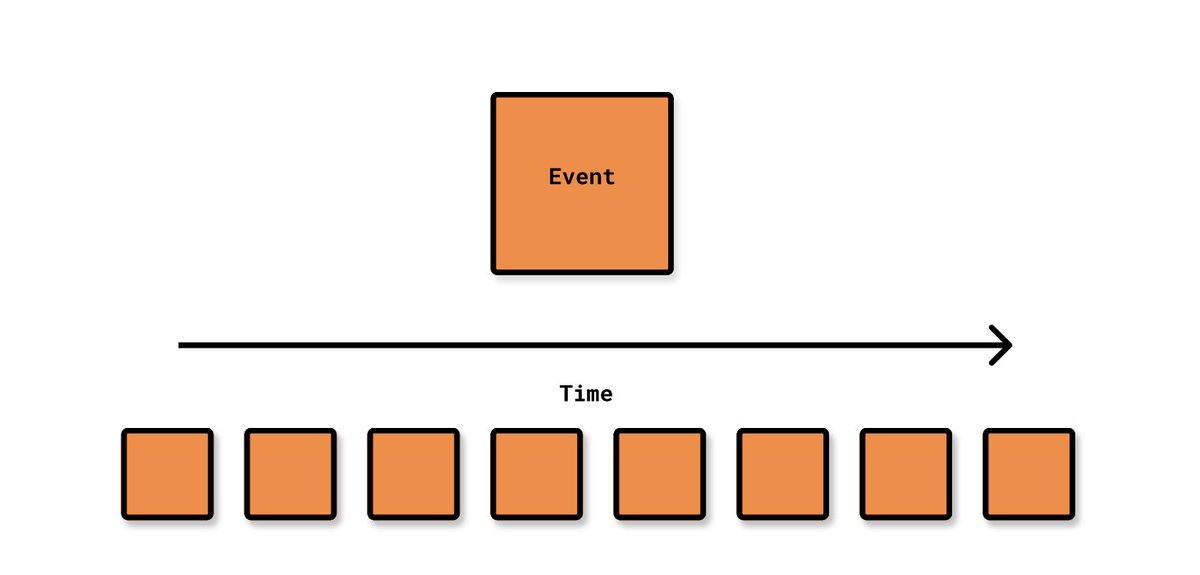
Events drawn out chronologically on a timeline from left to right.
💡Step 2. Commands
For each Domain Event, write the Command that causes it. These are your GraphQL mutations.
They should be in an imperative form. If you know the name of the role/actor that performs it, you can document that as well.
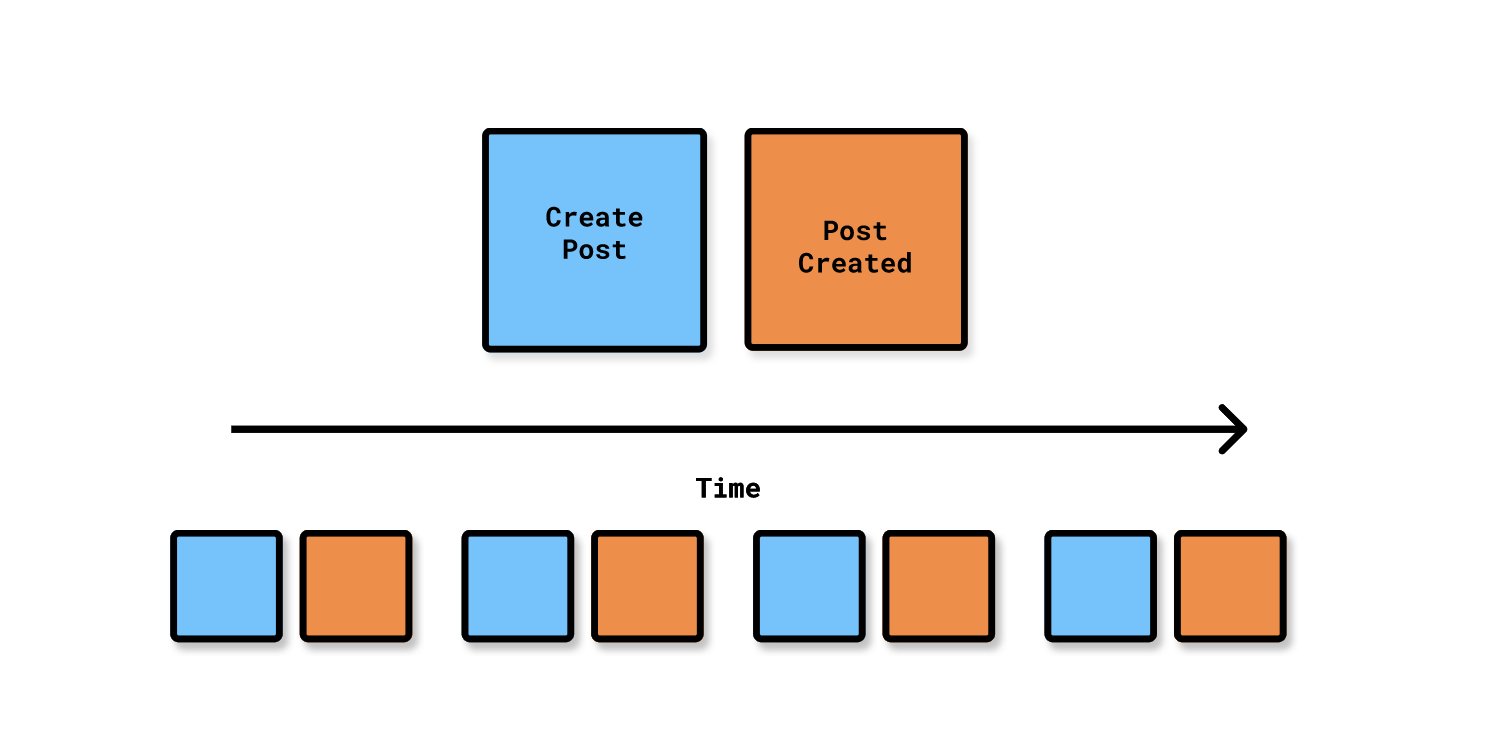
Commands accompanying their respective Domain Event chronologically on a timeline from left to right.
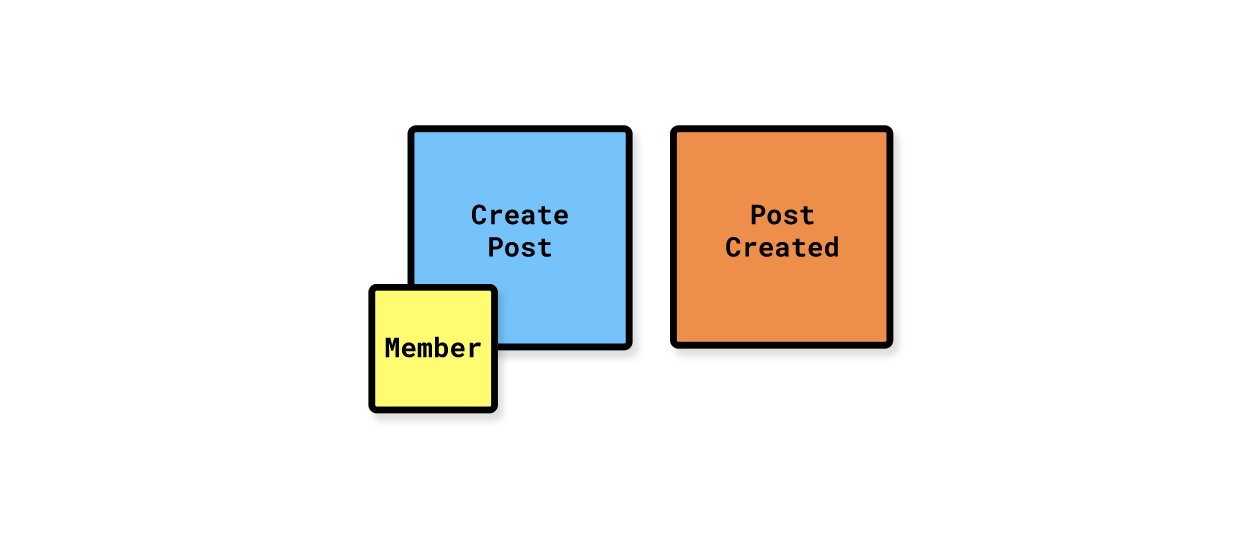
If you know the actor, that can be documented as well. Here, we know that Members are the only ones that are allowed to issue the Create Post command.
💡Step 3. Aggregates (write models)
For each Command/Domain Event pair, identify the Aggregate (or write model) that they belong to.
In Event Storming, we normally place the Aggregate (write model) above the Command/Domain Event pair.
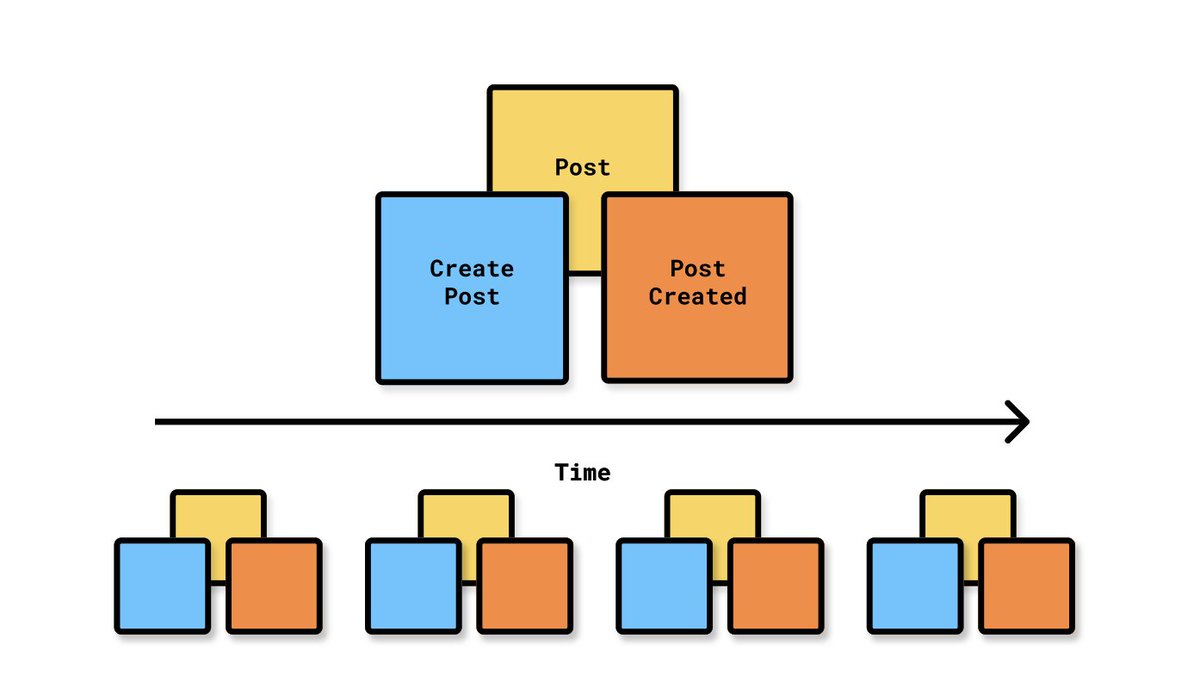
Commands accompanying their respective Domain Event chronologically on a timeline from left to right.
💡Step 4. Enforce boundaries & identify top-level fields
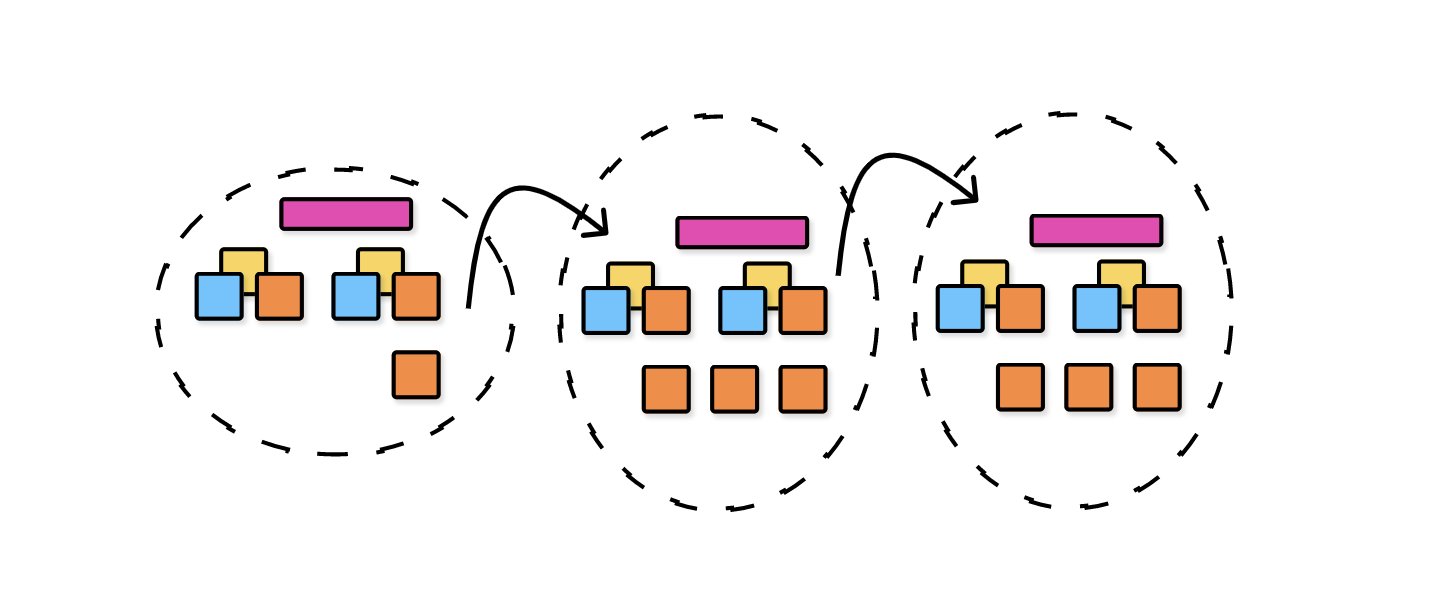
Identify the top-level GraphQL fields by applying Conway's Law. If you're building a Modular Monolith, these will be your subdomains. If you're working with Distributed Microservices, these will be your Federated GraphQL endpoints.
Segregate the Events, Commands, and Aggregate groups from each other based on the relevant self-organizing teams that play a part in the story of our application.
📖 This is probably the hardest and most misunderstood step. I'll create more documentation about this in the future. You may want to read about Conway's Law => (read here)
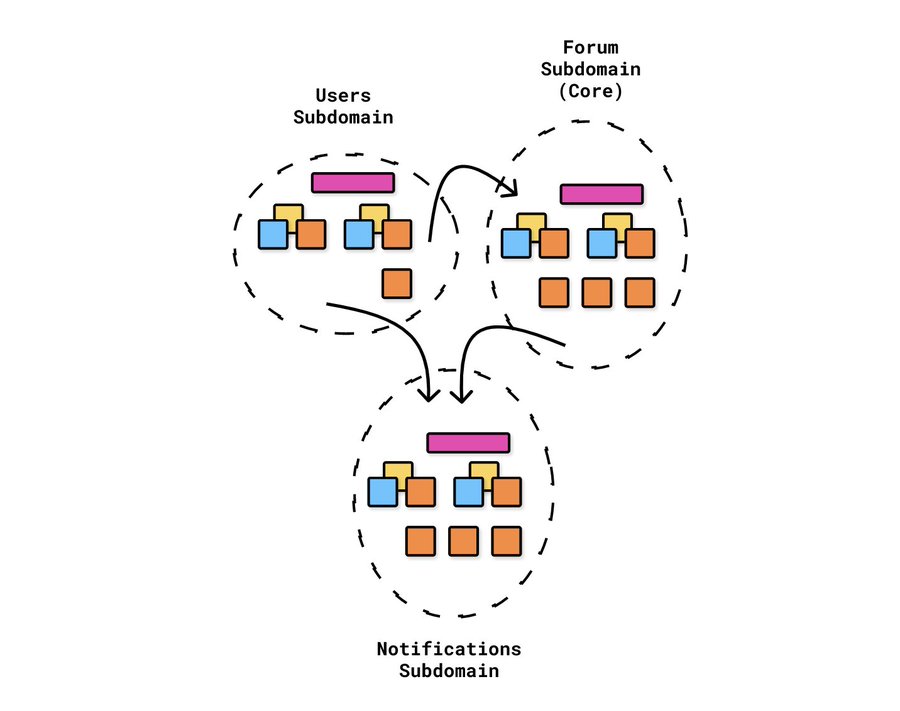
The story often flows between several subdomains/bounded contexts. For example, when a UserCreated event in the Users subdomain gets fired off, we subscribe and immediately issue a CreateMember command from the Forum subdomain.
💡Step 5. Identify Views / Queries
For each Aggregate, identify all possible Views (GraphQL queries) required in order to give users enough information to perform Commands (GraphQL mutations).
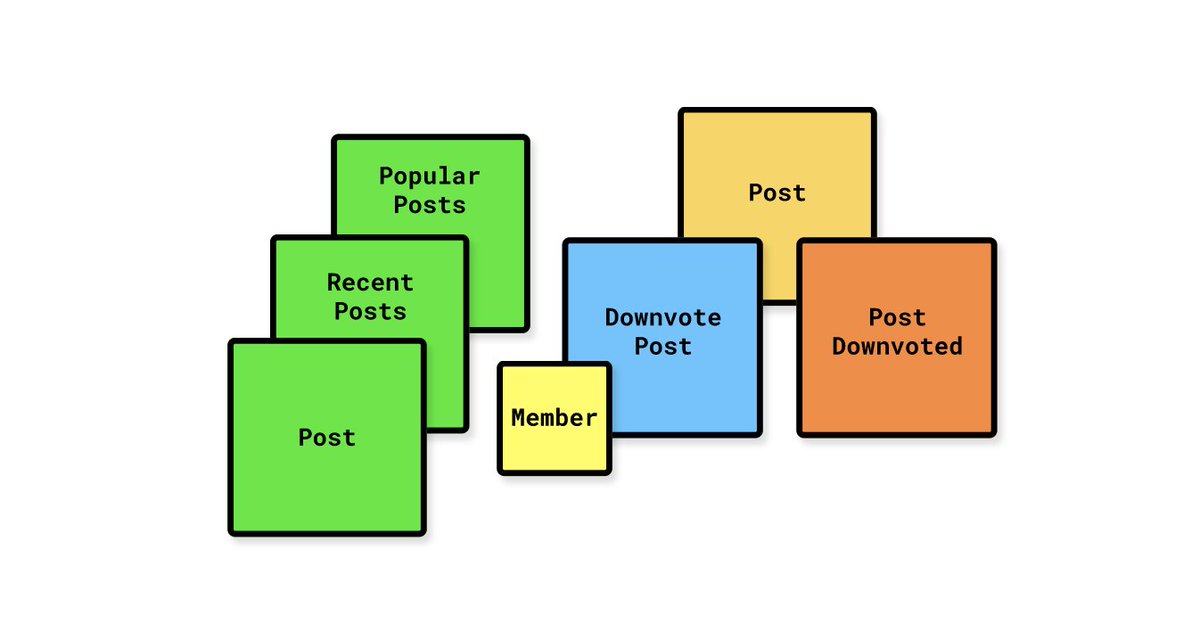
The Post aggregate has several different views.
💡6. Create the GraphQL Schema
Finally, create our GraphQL Schema from the discovered Commands (Mutations) and Queries.
In Modular Monoliths, you can break the schema up into separate files by extend-ing the Query and Mutation or by using graphql-modules.
infra/http/graphql/schemas/forum.ts
enum PostType {
text
link
}
type Post {
slug: String
title: String
createdAt: DateTime
memberPostedBy: Member
numComments: Int
points: Int
text: String
link: String
type: PostType
}
type Member {
memberId: String
reputation: Int
user: User
}
type PostCollectionResult {
cursor: String!
hasMore: Boolean!
launches: [Launch]!
}
extend type Query {
postById (id: ID!): Post
postBySlug (slug: String!): Post
popularPosts (pageSize: Int, after: String): PostCollectionResult
recentPosts (pageSize: Int, after: String): PostCollectionResult
memberById (id: String!): Member
}
extend type Mutation {
createPost (input: CreatePostInput!): CreatePostPayload
createMember (input: CreateMemberInput!): CreateMemberPayload
}
`For Federated GraphQL architectures, you can compose schemas using the @key directive that comes from @apollo/federation.
Final thoughts
Modeling with events when CRUD doesn't fit
This is a controversial opinion, but one I feel strongly about arguing. I believe that most naturally occurring systems don't naturally fit within the rigid confines of CRUD.
Complex systems are everywhere we look.
By definition, Julian Shapiro says that "a system is anything with multiple parts that depend on each other."
I'm not just talking about software. Consider these real world systems.
- Getting started at a new job: Applying to jobs, performing interviews, receiving offers, conducting negotiations, acceptances, paperwork, then (optional) relocation, onboarding/training.
- Buying a condo: Finding a place, getting approved for credit (if you don't get approved, you might have a new prerequisite goal - improve credit, earn capital, or ask relatives), making an offer, accepting an offer, signing paperwork, then making payments.
- Getting your driver's license: (Optionally) attending driving school, booking the test, passing the test (or failing the test and re-booking), getting your picture taken, getting your temporary license, then getting your license mailed to you.
As human beings, these systems don't seem that complex in the real world. The reason is because we tend to tame the complexity of them and how we progress through them by conceptualizing them as a series of events.
For example, before you accept a job, you need to have applied to jobs, performed an interview, and then gotten an offer.
See how those steps depend on each other? While I wish I could always just jump to the offer step, it's not possible.
Software systems often serve the singular purpose of making life easier for humans by consolidating the number of events that require human intervention.
Not sure where you are on the path? Take the Phases of Craftship quiz — 7 questions, personalized results.
Stay in touch!
Join 20000+ value-creating Software Essentialists getting actionable advice on how to master what matters each week. 🖖
View more in GraphQL