
An Introduction to Domain-Driven Design (DDD)

Also from the Domain-Driven Design with TypeScript article series.
Have you ever worked on a codebase where it felt like "the more code I add, the more complex it gets"?
Have you ever wondered, "how do you organize business logic anyways"?
Or have you ever been in the situation where you're nervous to add new code to an existing codebase in the fear that you'll break something else in a completely different part of the code somewhere?
What about enterprise companies? How are they doing it? Their codebases must be massive. How do they get anything done? How do they manage that complexity?
How are able they able to break off large bodies of code, assign them to teams, and then integrate all the teams together?
I've wondered all of this while coding on a 3 year old Node.js app with a line count pushing ~150K+.
I came across Domain-Driven Design when I realized I needed it the most.
Quick history about my experience with DDD
In 2017, I started working on an application called Univjobs, a marketplace for Canadian students and recent-grads to find co-op jobs, gigs and entry-level jobs and internships.
The MVP was pretty simple. Students could sign up, create their profile and apply to jobs. Employers could sign up, post jobs, browse students and invite them to apply to the jobs they've posted.
Since 2017, we've iterated many times, adjusting and encorporating features based on feedback from students and employers such as job recommendations, interviews, an Applicant Tracking System and several portals to integrate with the existing platform (developers, campus reps, etc).
Eventually, the codebase had became so large that adding new features on top of it took nearly 3x the amount of time it would have taken when I first started.
Lack of encapsulation and object-oriented design were to blame.
I had an Anemic Domain Model.

It was at this point I started to seek out solutions to the problem.
About Domain-Driven Design
Domain-Driven Design is an approach to software development that aims to match the mental model of the problem domain we're addressing.
The goals of DDD are as follows:
- Discover the domain model by interacting with domain experts and agreeing upon a common set of terms to refer to processes, actors and any other phenomenon that occurs in the domain.
- Take those newly discovered terms and embed them in the code, creating a rich domain model that reflects the actual living, breathing business and it's rules.
- Protect that domain model from all the other technical intricacies involved in creating a web application.
Initially conceptualized by Eric Evans who wrote the bible of DDD (famously known as the Blue Book), DDD's primary technical benefits are that it enables you to write expressive, rich and encapsulated software that are testable, scalable and maintainable.
Discovering the Ubiquitous Language
The Ubiquitous Language (which is a fancy DDD term for the common language that best describes the domain model concepts) can only be learned by talking with the domain experts. Once agreed upon, it enables developers to connect what the software implementation to what actually occurs in the real world.
If we're building an app that helps recruiters hire talent, we need to spend some time understanding the domain language and processes that exist from the recruiters' perspective.
That means actually talking to the domain experts.
Knowing the names of the constructs that we're about to model enables us to create rich domain models.
Modeling the Domain
There are huge payoffs in domain modeling. When our code lines up with the real life domain, we end up with a rich declarative design that will enable us to make changes and add new features exponentially faster.
Prerequisite Knowledge
You must at least this tall to ride this ride.
Jokes aside, Domain-Driven Design has a steep learning-curve. I won't lie about that.
Domain-Driven Developers need to be comfortable with the following:
- Object-Oriented Programming Basics
- Object-Oriented Programming Design Principles (composition > inheritance, referring to abstractions, SOLID Principles)
- General Design Principles (YAGNI, KISS, DRY)
Object-Oriented Programming is not strictly necessary to be successful with Domain Driven Design, but it does go with the natural contours of the patterns Domain-Driven Design has established.
To be able to move quickly, DDD does require some fundamental knowledge of software design patterns. It's a lot harder to do DDD well if we make a mess. That's why principles like YAGNI, KISS and DRY are even more important in order to iteratively improve a design.
The software design roadmap: Check out this roadmap I put together in order to figure out what you need to know in order to be most comfortable with Domain-Driven Design (which is right at the end of the roadmap).
In order to go fast, we must go well.
There is a construct for everything
Much of what makes frameworks so popular is that there is a pre-established way to do everything. When modeling the domain layer in DDD, there are already pre-established building blocks for every task.
See here for the list of building blocks for DDD applications.
Protecting the Domain Layer
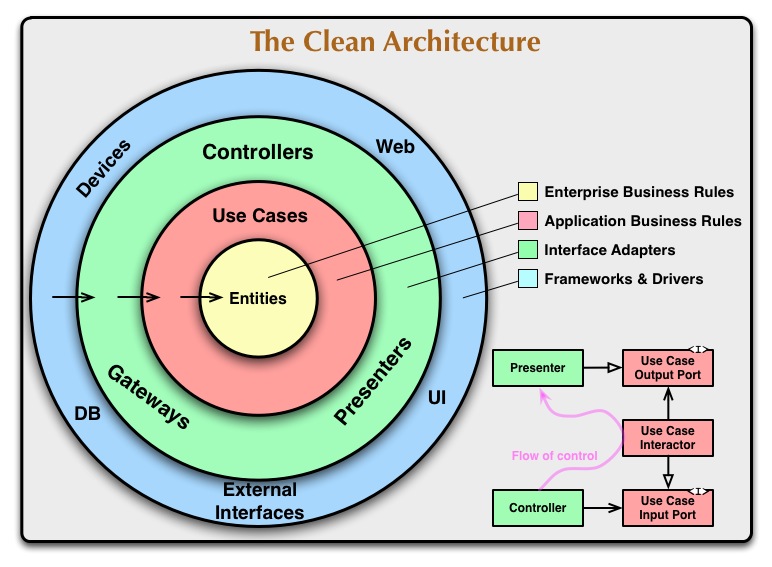
In order to do DDD well, we need to keep the SOLID principles in mind, organize a central domain layer at the core of our Layered Architecture and use a LOT of dependency inversion & injection in order to connect interface adapters to persistence, web and external technologies.
We don't want these infrastructrual things to sully our clean, fast, and testable domain model.
We want to keep frameworks, databases, caches, web servers, and anything else techy and not related to the domain model to a distance.
A large part of DDD is protecting the domain model by using a layered architecture. Check out this article on what each layer is responsible for.
JavaScript community on Enterprise Application Development
I studied Java in high-school and University. Like a lot of my peers, I didn't really LOVE Java a whole lot because:
a) We hated seeing red lines in the compiler all the time. This was scary for a 1st year University student learning how to program and
b) The community around Java appeared to be mostly focused on enterprise application patterns and frameworks. Concepts like POJOs, JavaBeans, dependency injection and aspect oriented programming were not cool nor did we aim to understand them or their uses (I should also mention, these were the early days of learning when some of us thought Java and JavaScript were the same thing 😜).
When I first picked up a book on Node.js and was introduced to JavaScript, I was blown away by all the cool things you can do with JavaScript, HTML and CSS.
The community was much more interesting than the Java community to me as a musician and a gamer (at the time).
Like many others, we learned how to build Node.js backends through YouTube, Scotch.io, Udemy and Udacity courses. This was also the extent to which a large number of developers from my generation learned about software design.
Model + view + controller.
This works great for a large number of RESTful web backends, but for applications where the problem domain is complex, we need to break down the "model" part even further1.
To do that, we use the building blocks of DDD.
Building Blocks
Very briefly, these are the main technical artifacts involved in implementing DDD.

Entities
Domain objects that we care to uniquely identify.
Things like: User, Job, Vinyl, Post, Comment, etc.
Entities live a life enabling them to be created, updated, persisted, retrieved from persistence, archived and deleted.
Entities are compared by their unique identifier (usually a UUID or Primary Key of some sort).

Value Objects
Value objects have no identity. They are attributes of Entities.
Think:
Nameas a Value Object on aUser.JobStatusas a Value Object onJobPostTitleas a Value Object onPost
Value Objects are compared by their structrual equality.
// A valid (yet not very efficient) way to compare Value Objects
const khalilName = { firstName: 'Khalil', lastName: 'Stemmler' };
const nick = { firstName: 'Nick', lastName: 'Cave' }
JSON.stringify(khalil) === JSON.stringify(nick) // falseAggregate
These are a collection of entities are that bound together by an aggregate root. The aggregate root is the thing that we refer to for lookups. No members from within the aggregate boundary can be referred to directly from anything external to the aggregate. This is how the aggregate maintains consistency.
The most powerful part about aggregates is that they dispatch Domain Events which can be used to co-locate business logic in the appropriate subdomain.
Domain Services
This is where we locate domain logic that doesn't belong to any one object conceptually.
Domain Services are most often executed by application layer Application Services / Use Cases. Because Domain Services are a part of the Domain Layer and adhere to the dependency rule, Domain Services aren't allowed to depend on infrastructure layer concerns like Repositories to get access to the domain entities that they interact with. Application Services fetch the necessary entities, then pass them to domain services to run allow them to interact.
Repository
We use repositories in order to retrieve domain objects from persistence technologies. Using software design principles like the Liskov Subsitution Principle and a layered architecture, we can design this in a way so that we can easily make architecture decisions to switch between an in-memory repository for testing, a MySQL implementation for today, and a MongoDB based implementation 2 years from now.
Factory
We'll want to create domain objects in many different ways. We map to domain objects using a factory that operates on raw sql rows, raw json, or the Active Record that's returned from your ORM tool (like Sequelize or TypeORM).
We might also want to create domain objects from templates using the prototype pattern or through the use of an abstract factory.
Domain Events
The best part of Domain-Driven Design.
Domain events are simply objects that define some sort of event that occurs in the domain that domain experts care about.
Typically when we're dealing with CRUD apps, we add new domain logic that we've identified by adding more if/else statements.
However, in complex applications that can become very cumbersome (think Gitlab or Netflix).
Using Domain Events, instead of adding more and more if/else blocks like this:
class UserController extends BaseController {
public createUser () {
...
await User.save(user);
// After creating a user, we handle both:
// 1. Recording a referral (if one was made)
if (user.referred_by_referral_code) {
// calculate payouts
// .. there could be a lot more logic here
await Referral.create({ code: this.req.body.referralCode, user_id: user.user_id });
}
// 2. Sending an email verification email
EmailToken.createToken();
await EmailService.sendEmailVerificationEmail(user.user_email);
// mind you, neither of these 2 additonal things that need to get
// done are particularly the responsibility of the "user" subdomain
this.ok();
}
}We can achieve something beautiful like this:

Using domain services (such as the ReferralFactoryService) and application services (such as the EmailService), Domain Events can be used to separate the concerns of the domain logic to be a executed from the subdomain it belongs.
Domain Events are an excellent way to decouple and chain really complex business logic.
Technical Benefits
- write testable business-layer logic
- spend less time fixing bugs
- watch a codebase actually improve over time as code gets added to it rather than degrade
- create long-lasting software implementations of complex domains
Technical Drawbacks
Domain modeling is time-consuming up front and it's a technique that needs to be learned.
Because it involves a lot of encapsulation and isolation of the domain model, it can take some time to accomplish.
Depending on the project, it might be more worthwhile to continue building an Anemic Domain Model. Choosing DDD coincides with a lot of the arguments I made for when it's right to use TypeScript over JavaScript for your project. Use DDD for #3 of the 3 Hard Software Problems: The Complex Domain Problem.
Conclusion
I'm really glad you're here and you're reading this.
If you're Junior Developer or getting started in the world of software architecture and design, I think you're on the right track.
Domain-Driven Design has introduced me to a world of software architecture, patterns and principles that I might not have naturally started learning until much later.
From my own experience, it's largely a "you don't know it until you need it" kind of thing where:
a) you realize you need to model a complex domain and it seems daunting so you try to find the right methology to approach it or
b) your codebase has become so large that it's hard to add new features without breaking new things, so you seek the solution to that problem or
c) someone more experienced than you brings it to your attention
d) you read my article and you realized you have an anemic domain model and you don't wish to have one.
The thing about Domain modeling is that it does take a little bit of time to start to get comfortable with. It can be a bit awkward to get accustomed to organizing your code this way, but when you start to reap the benefits of DDD, I think you'll naturally prefer to organize your backend code this way over the Anemic Domain Model and Transaction Script approach.
More in this series so far..
Understanding Domain Entities - DDD w/ TypeScript
Value Objects - DDD w/ TypeScript
Using UUIDs instead of Auto-Incremented Primary Keys
REST-first design is Imperative, DDD is Declarative [Comparison] - DDD w/ TypeScript
Intention Revealing Interfaces [w/ Examples] - Domain-Driven Design w/ TypeScript
How to Design & Persist Aggregates - Domain-Driven Design w/ TypeScript
Handling Collections in Aggregates (0-to-Many, Many-to-Many) - Domain-Driven Design w/ TypeScript
Challenges in Aggregate Design #1 - Domain-Driven Design w/ TypeScript
Does DDD Belong on the Frontend? - Domain-Driven Design w/ TypeScript
Where Do Domain Events Get Created? | Domain Driven Design w/ TypeScript
Decoupling Logic with Domain Events [Guide] - Domain-Driven Design w/ TypeScript
-
See this article on how to know when MVC isn't enough.
↩
Stay in touch!
Join 20000+ value-creating Software Essentialists getting actionable advice on how to master what matters each week. 🖖
View more in Domain-Driven Design