
Hash Tables | What, Why & How to Use Them
On this site, we're primarily concerned with software design, architecture, and the many problems that occur later on in your developer journey, like keeping code clean, handling complexity, and writing testable code.
Early on, when you're primarily concerned with learning the ins and outs of a language, you'll find yourself also need to master the algorithmic basis of software development — code in methods and functions. One of the most integral tools to solving these problems? Data structures.
I want to talk about one of the most important data structures: the hash table.
In this article, we’ll begin by learning what hash tables are and why you'd want to use them. Then we’ll look at different hash tables implementations and closely related data structures. Finally, we wrap with a discussion of which hash table implementation you should reach most of the time and discuss some of the most common use cases for hash tables.
What is a hash table?
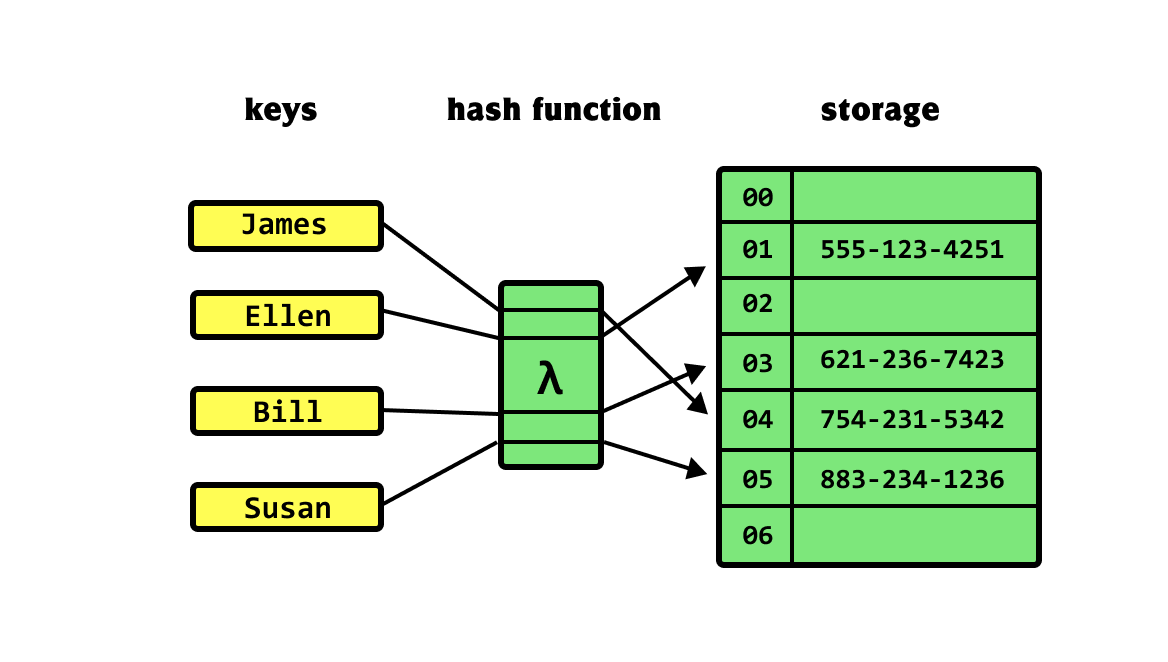
A hash table is a data structure that you can use to store data in key-value format with direct access to its items in constant time.
Hash tables are said to be associative, which means that for each key, data occurs at most once. Hash tables let us implement things like phone books or dictionaries; in them, we store the association between a value (like a dictionary definition of the word "lamp") and its key (the word "lamp" itself).
We can use hash tables to store, retrieve, and delete data uniquely based on their unique key.
Why use hash tables?
The most valuable aspect of a hash table over other abstract data structures is its speed to perform insertion, deletion, and search operations. Hash tables can do them all in constant time.
For those unfamiliar with time complexity (big O notation), constant time is the fastest possible time complexity. Hash tables can perform nearly all methods (except list) very fast in O(1) time.
| Algorithm | Average | Worst case |
|---|---|---|
| List | O(n) | O(n) |
| Search | O(1) | O(n) |
| Insert | O(1) | O(n) |
| Delete | O(1) | O(n) |
Because of this efficiency, you'll find hash tables to be pretty dang useful for many use cases. And if you look carefully, you’ll notice that they’re actually implemented in a variety of places throughout your tools like your databases, caches, data-fetching libraries, and so on.
We’ll expand on some of the uses cases for hash tables later on in the article.
How do hash tables work?
There are four distinct aspects to discuss how hash tables work:
- storage
- key-value pairs
- a hashing function
- table operations
Storage
A hash table is an abstract data type that relies on using a more primitive data type (such as an array or an object) to store the data. You can use either, but slight implementation implications occur depending on what you choose. We'll discuss those nuances in detail later on.
Key-value pairs
Regardless of the underlying primitive data structure, you use to store data, to store data as a value in a hash table, we need some way to identify it uniquely. We need a key.
Sometimes data contains an individual property that can very naturally assume responsibility for the key. For example, if we assume that a user has an email and a userId, then either the email or the userId could be used as the key if they are guaranteed to be unique.
{
email: 'khalil@khalilstemmler.com', // highlight
name: 'Khalil Stemmler',
userId: '2', // or this
phone: '555-123-4567'
}Other times, we're working with data where uniqueness is a little more ambiguous. Take, for example, the case of a dictionary again. Consider the dictionary definition for the word chair looks like this:
{
word: 'chair',
definition: `a separate seat for one person, typically with a back
and four legs.`
}What can we use for uniqueness here?
If we wish to store this in a hash table to quickly access the dictionary definition for the word, we'd have to use the word chair as the key itself.
However, based on this design, we cannot be sure to have uniqueness. Why? Because within the English language exists the idea of homonyms: words spelled (and sometimes pronounced) the same but with different meanings.
For example, there is another dictionary definition for the word chair.
{
word: 'chair',
definition: `the person in charge of a meeting or of an organization
(used as a neutral alternative to chairman or chairwoman).`
}See the problem here? If we merely use word as the key, then we cannot be sure it's unique. And uniqueness is important for retrieval to get access to the definition by providing the word. If we have two definitions for the same word, this probably has to influence how we shape our data.
We could solve this problem by changing how we choose to model our data.
{
word: 'chair',
definition: [
`a separate seat for one person, typically with a back
and four legs.`,
`the person in charge of a meeting or of an organization
(used as a neutral alternative to chairman or chairwoman).`
]
}If we wanted, it also wouldn’t hurt to improve the data structure even more by giving each definition a type and example property. This means that the data we store within the definition array would actually need to become an object.
{
word: 'chair', // the key to all of this data definition: [
{
type: 'noun',
example: 'no one occupied the seat, so I sat in it',
value: `a separate seat for one person, typically with a back
and four legs.`,
},
{
type: 'noun',
example: 'a three-year term as the board’s deputy chair',
value: `the person in charge of a meeting or of an organization
(used as a neutral alternative to chairman or chairwoman).`
}
]
}Great, so we have some data which can be uniquely identified, and we have some data that we’d like to store so that we can retrieve quickly.
Hash functions
Once we have the key-value pair, we pass them to the hash table to store the data for later retrieval. Hash tables need a hash function to determine how the table should store the data, and this is one of the standard hash table operations.
The hash function requires both key and the value.
The key contains the logic that determines what index the value will live at within the underlying data structure (array or object).
- When we use objects as storage, the index is often just some string or integer version of the key.
- When we're a fixed-size array as storage, we need to generate a hash code: a value that maps the key to a valid index/position in the array.
After deciding on an index, depending on how we've implemented it, the hash function can insert or merge the value at the position specified by the index.
For example, suppose our dictionary hash table had saved only one of the possible definitions for the word chair so far. In that case, we could configure the hash function to merge additional non-duplicate definitions to the chair value's definition when we try to hash it.
{
'cat': [...],
'chai': [...],
- 'chair': {
- type: 'noun',
- example: 'no one occupied the seat, so I sat in it',
- value: `a separate seat for one person, typically with a back
- and four legs.`,
- }
+ 'chair': [
+ {
+ type: 'noun',
+ example: 'no one occupied the seat, so I sat in it',
+ value: `a separate seat for one person, typically with a back
+ and four legs.`,
+ },
+ {
+ type: 'noun',
+ example: 'a three-year term as the board’s deputy chair',
+ value: `the person in charge of a meeting or of an organization
+ (used as a neutral alternative to chairman or chairwoman).`
+ }
+ ]
}Alternatively, we could also configure it to throw an error if the hash function encounters a duplicate. In implementations where we're not merging data, this is generally referred to as a collision.
Methods/operations (what can it do?)
We know that one of the operations a hash table should perform is to hash an item — that is, to create the unique index based on a key. What other things should it be capable of?
At the bare minimum, a hash table should be able to perform:
- add — add a key-value pair
- get — get a value by key
- remove — remove a value by key
- list — get all the keys (or key-value pairs)
- count — count the number of items in the table
How to choose the key in a hash table
To determine what should be the key in the key-value pair, it must be:
- Unique (e.g., yellow is a unique word — and though it has many definitions, we can store those definitions at the index created by the yellow key).
- known by the client in the world so that data can be re-retrieved (e.g., in storing the value, we must remember the key to re-retrieve it in constant time)
Basic JavaScript hash table examples
In this section, we’ll look at various ways to implement hash tables using JavaScript (and TypeScript). There are differences in languages like Java and Python (for example, in Java, you can use the HashMap interface as a part of the Java collection package). Still, ultimately, most general-purpose languages have a few different ways to implement a hash table.
Let's start with the simplest one.
Object implementation
The object implementation of a hash table in JavaScript is to merely lean on the usage of the plain ol' JavaScript object.
let table = {};There are a few ways the API allows us to add a key-value pair to our table. The first is to use the dot-property.
let table = {};
table.yellow = 'color between green and orange';
console.log(table); // { yellow: 'color between green and orange' }Another way is to use object brackets (which is useful when our key is numeric).
let table = {};
let pairOne = { key: 'yellow', value: 'color between green and orange' }
let pairTwo = { key: 2, value: { name: 'Bob' } }
// Text key
table[pairOne.key] = pairOne.value;
console.log(table); // { yellow: 'color between green and orange' }
// Numeric key
table[pairTwo.key] = pairTwo.value
console.log(table); // {
// yellow: 'color between green and orange',
// 2: { name: 'Bob' }
// }To see if a value is present, we can use the hasOwnProperty method that’s a part of every object in JavaScript.
let table = {};
table.yellow = 'color between green and orange';
table.hasOwnProperty('yellow'); // trueTo get the value of an item, we can call upon it using the key within either object brackets or with object dot notation.
let table = {};
table.yellow = 'color between green and orange';
console.log(table['yellow']); // 'color between green and orange'
console.log(table.yellow); // 'color between green and orange'When you're solving one-off algorithmic problems, you can use objects to get the functionality you need from a hash table quickly. However, there are better ways to design hash tables to be easier to use, and one such route is through encapsulation.
Encapsulated hash table
When you have related functionality, it's generally a good idea to encapsulate it within a cohesive object or a collection of functions. Here, we create a HashTable class that uses a plain object for storage and exposes all the necessary methods for a hash table.
class HashTable {
constructor() {
this.storage = {};
}
// Hash function
add(key, value) {
if (this.exists(key)) {
throw new Error(`${key} already exists`);
}
this.storage[key] = value;
}
get(key) {
if (!this.exists(key)) {
throw new Error(`${key} not found`);
}
return this.storage[key];
}
exists(key) {
return this.storage.hasOwnProperty(key);
}
remove(key) {
delete this.storage[key];
}
list() {
return Object.keys(this.storage).map((key) => ({
key,
value: this.storage[key],
}));
}
count() {
return Object.keys(this.storage).length;
}
}
let hashTable = new HashTable();
hashTable.add(1, "Bill");
hashTable.add(2, "Mary");
hashTable.add(3, "Samson");
console.log(`The hashtable has ${hashTable.count()} elements`);
console.log(`This is ${hashTable.get(2)}`);
hashTable.remove(1);
console.log(`The hashtable has ${hashTable.count()} elements`);
console.log(`Here are all the elements: ${hashTable.list()}`);The console output would look like the following:
The hashtable has 3 elements
This is Mary
The hashtable has 2 elements
Here are all the elements: [object Object],[object Object]Other similar data structures
Lots of languages have hash table-like data structures already defined into the language.
You may hear about:
- Hashmaps (Java)
- Maps
- Sets
- Dictionaries (Python)
Each of these are (more or less) the same thing as a hash table.
Associative array JavaScript hash table example (advanced)
Let's now look at a more advanced way to create hash tables using arrays as the backing data structure instead of objects.
We create a HashTable class and initialize a fixed-size array to 200 elements.
class HashTable {
constructor() {
this.table = new Array(200);
this.size = 0;
}
}Hash code
Next, let's implement the hash method. Assuming this is a private method used by all of the other public methods, its job is to create a hash code from a key.
A hash code is a value computed from the key which designates the index which the value should be saved at within the array.
In this implementation, the hash function expects a string key and returns a numeric hash code. Looking at each element in the string, we add the character codes to create a hash code.
// Assume the key is a 'string'
_hash(key) {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash;
}But how can we make sure that the hash value stays within the bounds of the array? One solution is to use the modulo operator to have the number roll around and never surpass the table length.
_hash(key) {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % this.table.length;
}Implementing the operations
Within the add method, we create a hash code to use as an index, and then we store both the key and the value within the array. We also increment the array size so we can tell how fully utilized the array storage is. We may want to resize it later when we get to a decent size utilization.
add(key, value) {
const index = this._hash(key);
this.table[index] = [key, value];
this.size++;
}For the get method, we'll rely on the hash function again to get the index for the value.
get(key) {
const index = this._hash(key);
return this.table[index];
}And then to remove an item, we merely remove the item from the array and decrement the size counter.
remove(key) {
const index = this._hash(key);
const itemExists = this.table[index] && this.table[index].length
if (itemExists) {
this.table[index] = undefined;
this.size--;
}
}A full associative array hash table implementation looks like the following:
class HashTable {
constructor() {
this.table = new Array(200);
this.size = 0;
}
_hash(key) {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % this.table.length;
}
set(key, value) {
const index = this._hash(key);
this.table[index] = [key, value];
this.size++;
}
get(key) {
const target = this._hash(key);
return this.table[target];
}
remove(key) {
const index = this._hash(key);
const itemExists = this.table[index] && this.table[index].length;
if (itemExists) {
this.table[index] = undefined;
this.size--;
}
}
}Let’s go ahead and test it out now.
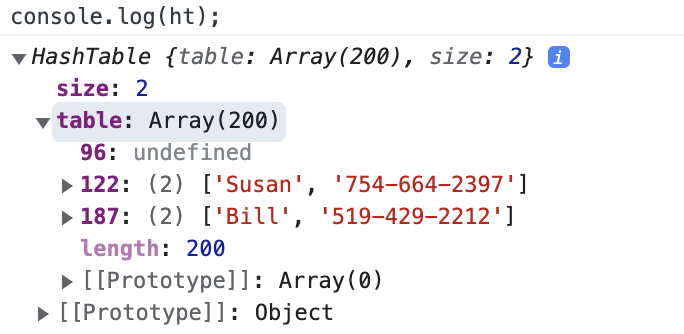
const ht = new HashTable();
ht.set("Bill", '519-429-2212');
ht.set("Kit", '647-232-1246');
ht.set("Susan", '754-664-2397');
console.log(ht.get("Bill")); // [ 'Bill', '519-429-2212' ]
console.log(ht.get("Kit")); // [ 'Kit', '647-232-1246' ]
console.log(ht.get("Susan")); // [ 'Susan', '754-664-2397' ]
console.log(ht.remove("Kit"));
console.log(ht.get("Kit")); // undefinedLooks good! If we were also to inspect the console afterward, here’s what the table could look like.
Collisions
A collision is when the hash function maps two or more key-value pair to the same storage index. As we populate the array, we’re bound to run into scenarios where collisions occur.
For example, if we were to run the following, we’d end up with a collision.
const ht = new HashTable();
ht.set("Susan", '754-664-2397');
ht.set("z", '555-123-5555');
console.log(ht.get("Susan")); // ['z', '555-123-5555']
console.log(ht.get("z")); // ['z', '555-123-5555']It appears we’ve overridden the “Susan” key with the “z”. This is very bad because it means we’ve lost data. And we don’t want that.
How does this even happen? Well, the reason why this happened is because the ASCII character for “z” is equal to the added ASCII characters in “Susan”. It’s 122.
To fix this, we’ll need collision detection (and optionally, array resizing) logic.
Collision detection and dynamic array resizing
It turns out that this is quite a challenging problem to solve. There are trivial approaches like just storing the same data in the same array index position and then merely traversing through it, but that increases the time complexity to O(n). As you'll discover down the road of writing your own hash table with associative arrays, there is no perfect approach to collision detection and dynamic array resizing.
There is one easy thing we can do, however. Using a prime number for the array (like 257, for example), we drastically reduce the likelihood of a collision.
If we had set the array size to 257 instead of 200, we’d get:
const ht = new HashTable();
ht.set("Susan", '754-664-2397');
ht.set("z", '555-123-5555');
console.log(ht.get("Susan")); // ['Susan', '754-664-2397']
console.log(ht.get("z")); // ['z', '555-123-5555']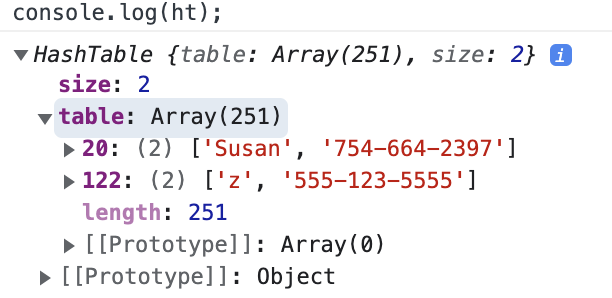
One technique for collision detection and resizing is called Prime Double Hash Table and it relies on the use of one smaller and one larger hash table. You can read here for more information on how this works.
Which implementation should I use?
For simplicity, I generally advocate you use one of the language's hash tables or encapsulate an object for storage instead of rolling your own associate array style hash table. Dealing with collisions and resizing is messy, and there are other more important things you need to spend your time coding.
When to use hash tables (use cases)
Not only are hash tables one of the first types of data structures you should reach for when solving problems in programming interviews, but their fast retrieval time makes them great for a variety of other use cases. Here are some common ones.
Databases (indexing)
Probably the most common use for hash tables is databases. To retrieve and increment through data in a database in a performant way, we need some way to identify it uniquely, and we need some way to index it.
In databases, we use indexes to locate data fast without needing to search through every single row. If a database has records from 0 to 100 and it knows that we're looking for 88, it doesn't need to start from 0 and traverse up to 88. It can begin the search from a much closer index.
Caching (backend)
Caching is a technique we use to speed up requests.
We separate read-like commands from write-like ones in Command Query Response Segregation (CQRS). We do this so that we can scale both sides independently.
On the read side, if we could tell that data hasn't changed yet (there haven't been any recent write-like operations — no commands), then there's an opportunity to optimize reads to the database.
In computing, reading from disk (database) takes longer than reading from memory (cache). Therefore, if we used an in-memory data store like Redis, we could speed up requests by offloading some of the reads to Redis instead.
Here's a Gherkins Given-When-Then (BDD-style) story to describe what should happen.
Feature: Caching
Scenario: Cache miss
Given a resource is not cached
When a read request comes in for the resource
Then the controller fulfils the request by going to the database
And the controller saves the resource to the cache for the next time
Scenario: Cache hit
Given a resource is cached
When a read request comes in for the resource
Then the controller fulfils the request by going to the cache
Scenario: Cache invalidation
Given a resource is cached
When a write request on the resource is performed
Then the cache invalidates the resource by removing it from the cache
Caching (front-end state management)
In the state management layer of a client-side application, we often find ourselves needing to persist, remove, and update data in storage.
Using tools like Apollo Client, Redux, or React hooks, the work we do to uniquely identify data and normalize it within our client-side cache is very similar to hashing function and persistence logic we write in hash tables.
Finding all unique elements
One other great use for a hash table is to find all unique elements among a list or collection of unorganized data.
Using some common aspects as the key, we can ensure that an item is only inserted once. Once that's done, we can merely iterate through the keys to get the entirety of the hash table's unique items.
Hash tables are a prevalent technique used in algorithm-based interview questions. As mentioned in Cracking the Coding Interview, hash tables should be one of the first data structures that come to mind for solving a potential challenge.
Storing transitions (transposition table)
This one is cool. Think about chess or other games where it may be essential to keep track of the entire sequence of moves made.
We can figure out any move's previous move in constant (O(1)) time with a transposition table. Assume a player's piece is at [1, 3]. How can we know what the previous move was? If we store moves like [xPosition, yPosition, moveNumber, player], we can use that as a key that maps to the previous position as a value.
For example:
- [1, 3, 5, 1] → [1, 4, 4, 1]
This says that player 1 is now at position [1, 3] as their 5th move. It also says that before their 5th move (their 4th), they were at [1, 4].
To retrieve the previous move, the hash function could easily find the index based on the player's piece's current position and the turn number. This is just an example; of course, there may be better ways to do this, but it should further illustrate the power of hash tables.
To learn more, read about transposition tables here.
FAQ
Hashtable vs. hashmap — what’s the difference?
Hash tables and hash maps are essentially the same things, and it just comes down to the methods you use and what you choose to use as your backing data structure.
People typically equate the idea of a hash table with that of the associative array approach. But people often associate the idea of a HashMap with the object approach.
Right? They do the same thing and ideally have the same time complexity, but it comes down to the methods and storage.
How do you create a hashmap in JavaScript?
We technically already did this with the object implementation example we first explored in this article. HashMaps are a specific type of data structure that exists in Java but (and hackily in JavaScript).
Without a HashMap abstraction, we can achieve similar behavior like this:
function createHashCode (object){
return obj.someUniqueKey; // Just an example
};
let dict = {};
dict[key(obj1)] = obj1;
dict[key(obj2)] = obj2;There is, however, the Map abstraction in JavaScript.
let map = new Map();
let obj1 = { value: 1 }
let obj2 = { value: 2 }
map.set(1, obj1);
map.set(2, obj2);
console.log(map.get(1));
// expected output: { value: 1 }
map.set(3, { value: 'billy' });
console.log(map.get(3));
// expected output: { value: 'billy' }
console.log(map.size);
// expected output: 3
map.delete(2);
console.log(map.size);
// expected output: 2Summary
In this article, we learned:
- That hash tables an abstract data structure that stores data in key-value pairs and can be used for fast data retrieval
- Hash tables can be implemented to have either an object or an array as the backing storage structure
- A key must be unique and readily queryable by the client
- The object implementation of a hash table is perhaps the simplest but languages like Java, Python, and TypeScript also have their own language-defined implementations of hash tables which can be used instead of rolling your own
- If using an array for the backing data storage of a hash table, one must be ready to perform collision detection and dynamic array resizing logic
- Hash tables are a common data structure in software engineering. They can be found or influenced in the design and implementation of databases, caching strategies, and more.
Not sure where you are on the path? Take the Phases of Craftship quiz — 7 questions, personalized results.
Stay in touch!
Join 20000+ value-creating Software Essentialists getting actionable advice on how to master what matters each week. 🖖
View more in Data Structures