
GraphQL Schemas vs. RESTful DTOs

In the last post, I mentioned the fact that DTOs (Data Transfer Objects) and GraphQL schemas serve a similar purpose; they create a strict abstraction layer that the client (web, mobile, or desktop apps) can rely on. This leaves backend services to merely figure out how to implement the data.
It creates a relationship that looks like this:

If you're a subscriber here, you know that I value the emails I get in response to my bi-weekly newsletters. One reader wasn't so convinced about the similarities between GraphQL schemas and RESTful DTOs in the last post and had some criticisms to share (thank you for doing so).
In this post, I'd like to examine those criticisms for GraphQL as a RESTful replacement and share some principles for managing graphs in production.
Opinion: GraphQL exposes everything
The first piece of criticism was:
"A DTO explicitly limits what is exposed to the client, whereas I'm finding with GraphQL that developers feel encouraged to expose everything but the kitchen sink up front."
Here, the reader is referring to the fact that to create a DTO, we need to explicitly type it out by hand.
For example, a DTO for a vinyl-trading application, say VinylDTO, could be composed to look like this:
type Genre = 'Post-punk' | 'Trip-hop' | 'Rock' | 'Rap' | 'Electronic' | 'Pop';
interface TrackDTO {
number: number;
name: string;
length: string;
}
type TrackCollectionDTO = TrackDTO[];
// Vinyl view model / DTO, this is the format of the response
interface VinylDTO {
albumName: string;
label: string;
country: string;
yearReleased: number;
genres: Genre[];
artistName: string;
trackList: TrackCollectionDTO;
}You may be looking at that and thinking, "man — this sure does look a lot like a GraphQL schema". And I'd opt to agree with you there. The GraphQL schema version of this might look like:
enum Genre {
PostPunk,
TripHop,
Rock,
Rap,
Electronic,
Pop
}
type Track {
number: Int!
name: String!
length: String!
}
type Vinyl {
albumName:String!
label: String!
country: String!
yearReleased: Int!
genres: [Genre!]!
artistName: String!
trackList: [Track!]!
}So where are we getting the "developers feel encouraged to expose everything but the kitchen sink upfront" sentiment from?
I think it's coming from the fact that there are tools out there to auto-generate GraphQL CRUD APIs for you. In those cases, if you're intending to use your auto-generated GraphQL API as your public GraphQL API, then yes — you're exposing everything to the client.
But this simply just isn't the way we recommend building GraphQL APIs at Apollo.
Have you read Principled GraphQL?
Principled GraphQL
Principled GraphQL is Apollo's best practices guide for creating, maintaining, and operating a data graph. It's what we practice and preach at Apollo.
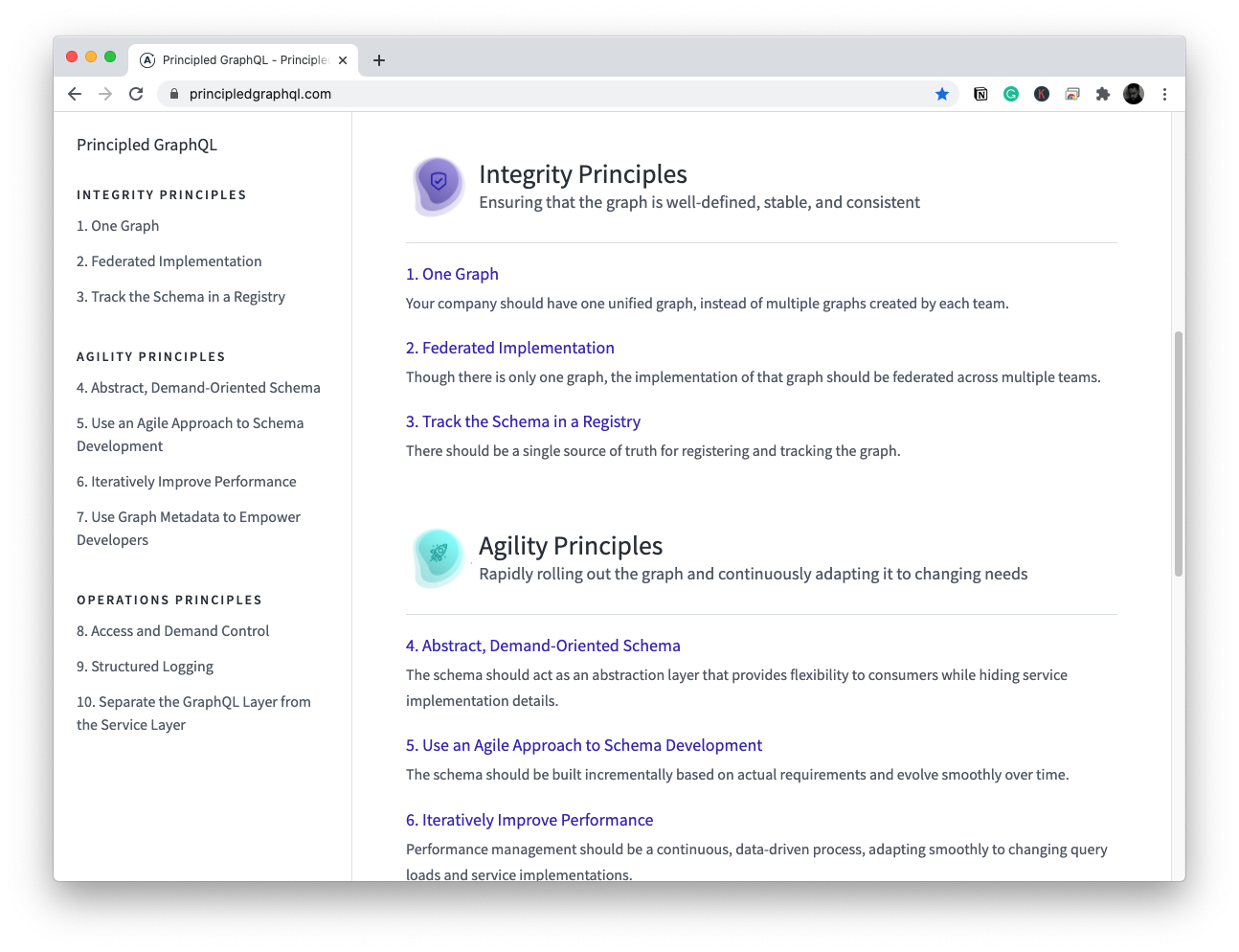
As someone who maintains a website about software design principles and best practices, I really respect the fact that Principled GraphQL puts a stake in the ground for what it means to do GraphQL properly. It's written by the founders of Apollo based on thousands of conversations with developers implementing GraphQL at companies of all sizes. Conversations with those with practical experience; now that's the way to discover phronesis.
Principle #5 is:
Use An Agile Approach to Schema Development
One of the main ideas about this principle is that "each field should be added only in response to a concrete need by a consumer for additional functionality".
This means that schema design is an iterative process and you should only be adding things to your graph that is actually needed by the consumers of your graph. This means collaboration. It means conversations. This is "Domain-Driven GraphQL Schema Design".
Any field not explicitly and decidedly needed by the client is an implementation detail. It's likely that there are some things in your database that shouldn't be exposed to the client directly. For example, if you were doing CQRS, in a command, there could exist an invariant within an aggregate that operates on a particular piece of state that doesn't have a read model equivalent. Consider an insurance application. You might assign a user a score and save that to their profile. Perhaps it determines what they get approved for. Perhaps this is something that you don't want to expose to the client directly.
Opinion: You can't change already added fields
The other main piece of criticism I noticed was that you can't change fields. They said:
"The server must still maintain all of the fields it initially made available or risk breaking clients", and "now there is no backing out."
I can see why you'd think that, but there is backing out.
GraphQL APIs are tasked with the same set of challenges that any API layer technology is tasked with. Among those challenges, the big question of "how do we make changes to the API and deprecate parts of it over time" arises.
Well, in GraphQL there's no concept of an API version like v1 or v2 in REST. Such a way to version your API is coarse and can become quite an engineering effort.
Instead, GraphQL gives you a declarative and fine-grained way to keep track of, evolve, and deprecate parts of your API.
Use a schema registry
Principle #3 is to:
Track the Schema in a Registry
Similar to how we track source code in Git, the idea is that we should be tracking what our graph looks like overtime in a schema registry.

I highly recommend the talk, "The Do's and Don'ts of GraphQL Schema Design" by Michael Watson — Solutions Engineer at Apollo.
The schema registry keeps track of the history of the graph and it can be used to model graph variants (like example, staging, production, or dev branches).
How to track your schema in a registry: You can get started with a local dev graph in Apollo Studio and then publish variants of your graph to a managed schema registry when you're ready. Read the docs on schema reporting and get started with a local graph here.
Now, if you're familiar with REST — you've probably set up different example, staging, and production environments before. Not much difference there besides a more explicit and declarative way to do this.
The next part is uniquely GraphQL.
Deprecating fields
You can deprecate old fields. Here's what that might look like in your schema:
type ExampleType {
oldField: String @deprecated(reason: "Use `newField`.")
newField: String
}GraphQL gives you the ability to deprecate fields, signaling to clients that they should probably use the new fields, with GraphQL directives.
That's great and all, but how do we do this safely?
Client awareness
Apollo has a cloud platform with a variety of tools that help you build, explore, and manage your graph in production: it's called Apollo Studio.
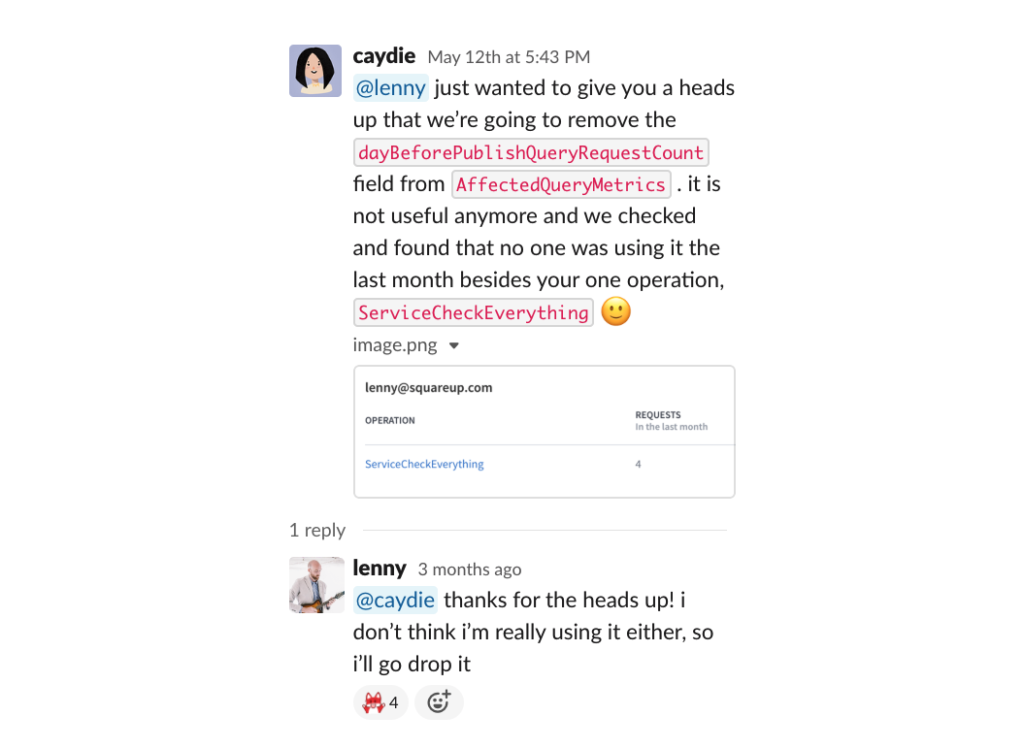
One of the many features in Apollo Studio is GraphQL "Client Awareness". Client awareness lets you know ahead of time which clients are using which fields in your Graph and how much traffic those fields get.
This is probably one of the safest ways to know when you can pull a deprecated field from your graph.

With this tool, a workflow to deprecate and update a field might look like this:
- Create a new field and deprecate the old one using the
@deprecateddirective (perhaps optionally recommending the new field to use instead). - Publish the graph changes to a schema registry.
- Give teams time to start using the new field.
- Check Apollo Studio to confirm that the new field's traffic is ~zero.
- Create a PR to remove the old field.
- Deploy the change to production.
Conclusion
GraphQL schemas create a strict abstraction layer between the client and the backend services, similar to DTOs in REST. Since they're both API layer constructs, they share a lot of the same problems. What we've found makes the real difference is a principled approach and great tooling.
Recommended
Not sure where you are on the path? Take the Phases of Craftship quiz — 7 questions, personalized results.
Stay in touch!
Join 20000+ value-creating Software Essentialists getting actionable advice on how to master what matters each week. 🖖
View more in GraphQL