
When to Use Mocks: Use Case Tests

If you're not familiar with mocking, it's a pretty controversial topic in testing.
Mocking implies the use of some sort of test double which we sub in for real components. When you're testing, you obviously want to get as much confidence as possible that your code is working correctly, right? So then, why would we bother using mocks if all it's going to do is reduce your confidence?
A reader sent in a question expressing his concern to me recently. He said,
Mocking vs stubbing has always caused conflict with me, because to me it seems that mocking violates the fact that we are only interested in testing the external api/contract of a code module as it tests whether specific internal functions were called. If I am not mistaken, when we desire to test a function/method, we are not interested in what other functions/methods it calls, but only in providing the correct output. Please correct me if I am wrong.
You’re right on the money. Mocking alone isn't the best way to test an application. However, mocking does have benefits when used as a part of a larger testing strategy. Let's explore.
Prerequisites
- You're familiar with test doubles and know the the difference between mocks and stubs.
The correct conceptual model of OO
We have to constrain this discussion to the idea of OO, because mocking is a lot less useful in FP. It’s just an entirely different conceptual model.
The conceptual model you should have with OO is one of a “web of objects”, or like as Alan Kay had initially imagined, cell biology. Think of objects as cells each with their own tiny little “mini-computers” and encapsulated state within them. You can even think of it as routers in a computer network.
How you should really think of OO, as a "Web of Objects"
Behaviour is realized through the messages. For example, cell A tells cell B to do something (which may delegate some work to cell C without cell A needing to know that happened).
What do we have to test?
In a layered architecture, we have to test:
- Incoming adapters (GraphQL, REST, incoming webhooks)
- Managed outgoing adapters (application database)
- Unmanaged outgoing adapters (message bus, email/notification service or other public API calls)
- The application core (use cases)
- Domain objects (entities, value objects, domain services)
Because each of these tests need to verify different things, we have to use different testing strategies for each one.
Let's focus specifically on #4, testing the application core use cases. But first, we have to discuss some of the underlying philosophy for how to use test doubles correctly.
Command-query separation
Use cases are the features of our applications. If you'll recall, features can be either commands or queries, as per the CQS principle.
Commands are unique from queries in the sense that they perform a state change. It could be saving an entity to a database, queuing an email, saving an event to some event storage, and so on.
Ultimately the rule with test doubles with respect to CQS is that we:
Use mocks for commands, use stubs for queries
And when it comes to performing assertions, we:
Do not perform assertions on queries. Assert only results and that commands were invoked using mocks.
These rules are in place to ensure that your tests aren't susceptible to ripple. It's to prevent you from writing the brittle sort of test that asserts against implementation details. And since query-like operations can be seen as implementation details, we create brittle tests when we assert against them.
In testing a use case, our goal is to test 1) that the outgoing interactions - the commands - were issued from our application core, and 2) we get the intended outcome for the scenario.
Writing a use case test
Let's assume you have a use case that you need to implement using TDD. You even have the functional requirements written out using Gherkin in Given-When-Then format.
Feature: Make offer
Scenario: Making a monetary offer
Given a vinyl exists and is available for trade
When a trader wants to place an offer using money
Then the offer should get created
And an email should be sent to the vinyl ownerFantastic. We know, at a high-level, from the user's perspective, one of many scenarios for this use case that we'll need to test.
As you likely know, the TDD process is to start with a failing test, make it pass, and then refactor it. Where a lot of developers get stuck is trying to figure out how exactly to write tests for this, especially because the solution is going to involve databases, external services, and other infrastructural concerns that will slow down tests and cause it to no longer be a unit test.
What's not a unit test?: Michael Feathers says a test is not a unit test if:
- It talks to the database
- It communicates across the network
- It touches the file system
- It can’t run at the same time as any of your other unit tests
- You have to do special things to your environment (such as editing config files) to run it.
This constraint moves our discussion to the two general flavours of TDD - two ways we can write tests: inside-out and outside-in.
Outside-in vs inside-out
- Inside-out — Most of us are familiar with this. It's when we start from the inside layers where code is pure and doesn't involve infrastructure. We unit test outwards. This is typically what we think of when we consider regular unit tests. It's also known as Classic TDD. You can see a demonstration of this here.
- Outside-in — This is when we start from the outer boundary, have some understanding of the layers of our application, and code inwards.

If we're to start at the use case boundary, it's impossible for us to write a unit test with the inside-out approach. Since we rely on infrastructure (like databases, web services, and external services), we will fundamentally break a rule of unit tests. Use cases test the core application functionality. They fetch domain objects so that inner layer objects (domain) can execute the essential complexity of the problem at hand. We want these tests to be fast - not painful, show, flaky, and hard to configure.
To write a use case test (that can still technically be seen as a unit test) means we have to use the outside-in approach (the mockist approach).
Starting with the outcomes (commands/state-changes)
With any test, we have to stop and think about the outcomes first. These will be either command-like operations or the output result (success or failure) returned from the use case.
First of all, we expect the use case to be successful in this scenario, so there's that.
But if we look back to our acceptance criteria for this test, we'll notice that are two commands:
- the offer should get created
- an email should be sent to the vinyl owner
Some TDD-practioners advocate for starting with the assert phase of the "arrange-act-assert" structure of a test. The reason? Often, when we start with creating the objects, it's a lot harder to maintain YAGNI and it forces the design into things that aren't actually necessary for us to accomplish the behavior. Once you get comfortable writing tests using TDD, I also advise this technique.
Here's what the start of our outside-in test could look like.
// modules/trading/useCases/makeOffer/makeOffer.spec.ts
describe('makeOffer', () => {
describe(`Given a vinyl exists and is available for trade`, () => {
describe(`When a trader wants to place an offer using money`, () => {
test(`Then the offer should get created and an email should be sent to the vinyl owner`, async () => {
// Arrange
// Act
// Assert
expect(result.isSuccess()).toBeTruthy(); // result expect(mockTradesRepo.saveOffer).toHaveBeenCalled(); // outcome expect(notificationsSpy.getEmailsSent().length).toEqual(1); // outcome expect(notificationsSpy.emailWasSentFor()) .toEqual(result.getValue().offerId); // outcome });
});
});
});At this point, we are very much in the red of the red-green-refactor loop. I'm referring to objects that don't exist, but that's completely OK, because that's what we're supposed to do. We're not too concerned about how we'll make this work. At this point, we're concerned about how we'll know that it worked. That's the big thing you get when you write test-first.
Here's what we're doing:
- I'm assuming that we'll get a result object back from the use case. I'm assuming this result will be successful.
- I'm also writing about a collaborator called a
mockTradesRepo, and because one of the requirements is that the "offer should get created", I know that the command (the object-oriented message we'll send to a realTradesRepo) will be calledsaveOffer. We expect that to have been called. - Lastly, I used my imagination to consider how I could ascertain that an email was sent and that it was sent in the correct context. If we return the
offerIdin the result, we can link that to the email. I need a mock object here, but I know that a hand-rolled mock object, one that we write custom test methods on is actually called a spy, we name thenotificationsRepomock object anotificationsSpyaccordingly.
Acting out the behavior
Continuing to work backwards, we'll act out the behavior to make this thing work. I'm specifically focused on the when part of the Given-When-Then statement: "When a trader wants to place an offer using money".
I write something like the following:
// modules/trading/useCases/makeOffer/makeOffer.spec.ts
describe('makeOffer', () => {
describe(`Given a vinyl exists and is available for trade`, () => {
describe(`When a trader wants to place an offer using money`, () => {
test(`Then the offer should get created and an email should be sent to the vinyl owner`, async () => {
// Arrange
// Act
let result = await makeOffer.execute({ vinylId: '123', tradeType: 'money', amountInCents: 100 * 35, });
// Assert
expect(result.isSuccess()).toBeTruthy();
expect(mockTradesRepo.saveOffer).toHaveBeenCalled();
expect(notificationsSpy.getEmailsSent().length).toEqual(1);
expect(notificationsSpy.emailWasSentFor())
.toEqual(result.getValue().offerId);
});
});
});
});So far so good.
Create the subject and collaborators in the arrange phase
There are a couple of objects we need to create here:
- Subject: The
MakeOfferuse case which returns a result. - Collaborator #1: The
TradesRepo(which we will mock). - Collaborator #2: The
NotificationService(which we will mock with a spy)
Here's where we merely create these objects and focus on getting our code to at least compile.
// modules/trading/useCases/makeOffer/makeOffer.spec.ts
import { ITradesRepo, MakeOffer } from './makeOffer';import { NotificationsSpy } from './notificationSpy';import { createMock } from 'ts-auto-mock';
describe('makeOffer', () => {
describe(`Given a vinyl exists and is available for trade`, () => {
describe(`When a trader wants to place an offer using money`, () => {
test(`Then the offer should get created and an email should be sent to the vinyl owner`, async () => {
// Arrange let mockTradesRepo = createMock<ITradesRepo>(); let notificationsSpy = new NotificationsSpy(); let makeOffer = new MakeOffer( mockTradesRepo, notificationsSpy, );
// Act
let result = await makeOffer.execute({
vinylId: '123',
tradeType: 'money',
amountInCents: 100 * 35,
});
// Assert
expect(result.isSuccess()).toBeTruthy();
expect(mockTradesRepo.saveOffer).toHaveBeenCalled();
expect(notificationsSpy.getEmailsSent().length).toEqual(1);
expect(notificationsSpy.emailWasSentFor())
.toEqual(result.getValue().offerId);
});
});
});
});Here we have the interface for the TradeRepo:
interface ITradesRepo {
saveOffer(offer: any): Promise<void>;
}And here we have the spy for the NotificationsService:
export class NotificationsSpy implements INotificationService {
private emailsSent: Email[];
constructor() {
this.emailsSent = [];
}
public async sendEmail(email: Email): Promise<void> {
this.emailsSent.push(email);
}
getEmailsSent() {
return this.emailsSent;
}
emailWasSentFor () {
if (this.getEmailsSent().length === 0) throw new Error('No emails sent');
if (this.getEmailsSent().length > 1) throw new Error("More than one email sent");
return this.getEmailsSent()[0].originatingId;
}
async hello() {}
}The NotificationService interface:
export type Email = { originatingId: string };
export interface INotificationService {
sendEmail(email: Email): Promise<void>;
}And a minimal, trivial implementation of the MakeOffer use case.
// modules/trading/useCases/makeOffer/makeOffer.ts
export class MakeOffer {
constructor(
private tradesRepo: ITradesRepo,
private notificationService: INotificationService,
) {}
async execute(request: any) {
...
}
}That should let our code compile.
We're still pretty red but now, we can focus on getting to green.
ts-auto-mock: You may notice that we're using ts-auto-mock instead of Jest to create mocks. I wrote about why we're doing this in How to Mock without Providing an Implementation in TypeScript.
Adding stub objects
As we start to implement the MakeOffer use case, we realize that we can't really do this without the existence of a VinylRepo of some sort to actually fetch the vinyl entity and determine if it's available for trade or not.
// vinylRepo.ts
export interface IVinylRepo {
getVinylOwner(vinylId: string): Promise<Trader | Nothing>;
isVinylAvailableForTrade(vinylId: string): Promise<boolean>;
}// modules/trading/useCases/makeOffer/makeOffer.spec.ts
import { ITradesRepo, IVinylRepo, MakeOffer } from './makeOffer';import { NotificationsSpy } from './notificationSpy';
import { createMock } from 'ts-auto-mock';
describe('makeOffer', () => {
describe(`Given a vinyl exists and is available for trade`, () => {
describe(`When a trader wants to place an offer using money`, () => {
test(`Then the offer should get created and an email should be sent to the vinyl owner`, async () => {
// Arrange
let fakeVinylRepo = createMock<IVinylRepo>(); let mockTradesRepo = createMock<ITradesRepo>();
let notificationsSpy = new NotificationsSpy();
let makeOffer = new MakeOffer(
fakeVinylRepo, mockTradesRepo,
notificationsSpy,
);
// Act
let result = await makeOffer.execute({
vinylId: '123',
tradeType: 'money',
amountInCents: 100 * 35,
});
// Assert
expect(result.isSuccess()).toBeTruthy();
expect(mockTradesRepo.saveOffer).toHaveBeenCalled();
expect(notificationsSpy.getEmailsSent().length).toEqual(1);
expect(notificationsSpy.emailWasSentFor())
.toEqual(result.getValue().offerId);
});
});
});
});And the use case changes to:
// modules/trading/useCases/makeOffer/makeOffer.ts
export class MakeOffer {
constructor(
private vinylRepo: IVinylRepo,
private tradesRepo: ITradesRepo,
private notificationService: INotificationService,
) {}
async execute(request: any) {
...
}
}It's good that we're discovering this later after we've already written out what we're going to assert: the command-like operations and the result for the use case. Sometimes, when we start with creating the objects in the "arrange" phase, we're tempted to assume that the objects which perform queries are somehow important to validating the correctness of our tests.
For example, in an earlier version of this very post, I was doing this:
expect(fakeVinylRepo.getVinylOwner).toHaveBeenCalledWith('123')This leads to brittle, hard-to-maintain tests because the queries have nothing to do with the outcomes (state changes + result). If the implementation changes, then we experience ripple and up having to change our tests. And that's yucky. Special thank you to Steve in the comments section for pointing this out.
Double loop TDD and turning this test green
Great start.
Is this enough? Absolutely not. This test will not pass until we have gone in, fleshed out the rest of the MakeOffer use case, and probably also end up creating domain entities for Email, Offer, and probably Vinyl too (each of which we should be unit testing with the inside-out approach).
Some call this approach to TDD double loop TDD. You have an outer loop (the one that we've been writing in this post so far) which shapes the way the use case could work and exercises the scenarios (these are often the acceptance tests), and you have the inner loop which ensures that the smaller, pure domain objects are properly tested as well.
This means that the outer TDD loop stays red for much longer than the inner TDD loop. But once both the outer and inner loops pass, you're done that scenario.
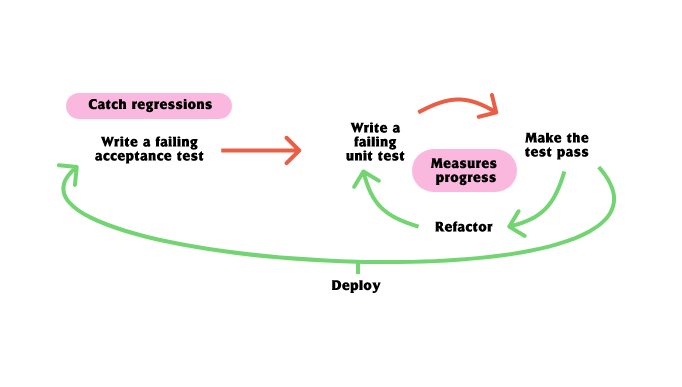
This is a powerful tool for your toolbox, but it is important to remember that it is not mutually exclusive to the classic (chigago-Kent Beck) style of TDD where you pass in real objects.
Integration tests and managed/unmanaged dependencies: There is much to test in a clean (hexagonal, onion, ports and adapters, layer) architecture and it can get pretty complicated to explain. There are incoming adapters and outgoing adapters. Incoming adapters are things like GraphQL and REST. Outgoing adapters are things like databases or facades that we're written to external services like Stripe and so on. Each of these out-of-process, external dependencies are said to be either a managed or unmanaged dependency. Depending on the type, we write different kinds of tests for them. For example, repository objects (adapters to our application database), are managed output adapters. The best way to test it is to confirm that it adheres to contract of the interface - that is, to perform a contract test. Read about managed and unmanaged dependencies here and what each type of test in a testing strategy is for, below.
Using stubs to force code paths
We know that most use cases have typically one happy path and numerous sad paths. By adjusting the input data and setting up stubs to return different data in different contexts, we get the ability to force our code through paths to see if our use cases return the correct error result (on failure) or invoke the commands on dependencies in success cases (as we've seen here).
For example, in ddd-forum, a forum application, look at all the different ways a DownvotePost use case can fail.
import { Either, Result } from "../../../../../shared/core/Result";
import { DownvotePostErrors } from "./DownvotePostErrors";
import { AppError } from "../../../../../shared/core/AppError";
export type DownvotePostResponse = Either<
DownvotePostErrors.MemberNotFoundError |
DownvotePostErrors.AlreadyDownvotedError |
DownvotePostErrors.PostNotFoundError |
AppError.UnexpectedError |
Result<any>,
Result<void>
>We have to exercise these paths with tests. So we better have the ability to be nimble with our tests.
Part of a larger testing strategy
One of the main ideas why we use a layered architecture is because of the testing options it gives us. Ultimately, you can think of your application as core and infrastructure.
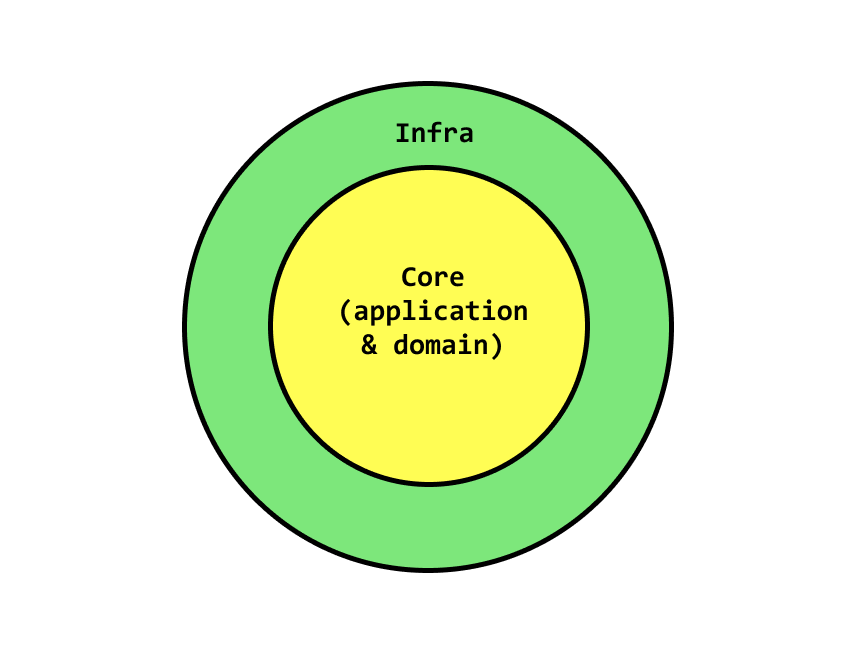
If you understand and enforce boundaries between these two types of code, you have a myriad of ways to set up a testing strategy for your application. Here’s one for a full stack GraphQL + React application for example:
- Unit test all smaller, pure, core components like entities, domain services, aggregates, value objects, utility classes and so on
- Also unit test your use cases with mocks to confirm that we perform commands against infrastructure dependencies; use stubs to force code to go down different code paths — do this for all of your acceptance tests
- Integration test all of your incoming and outgoing adapters (GraphQL API, database, cache, event subscribers, etc)
- End to End test — from the front-end to the GraphQL API, through the database and the cache — a select few acceptance tests to get that extra bit of confidence
With that said, your testing strategy could look something like this:
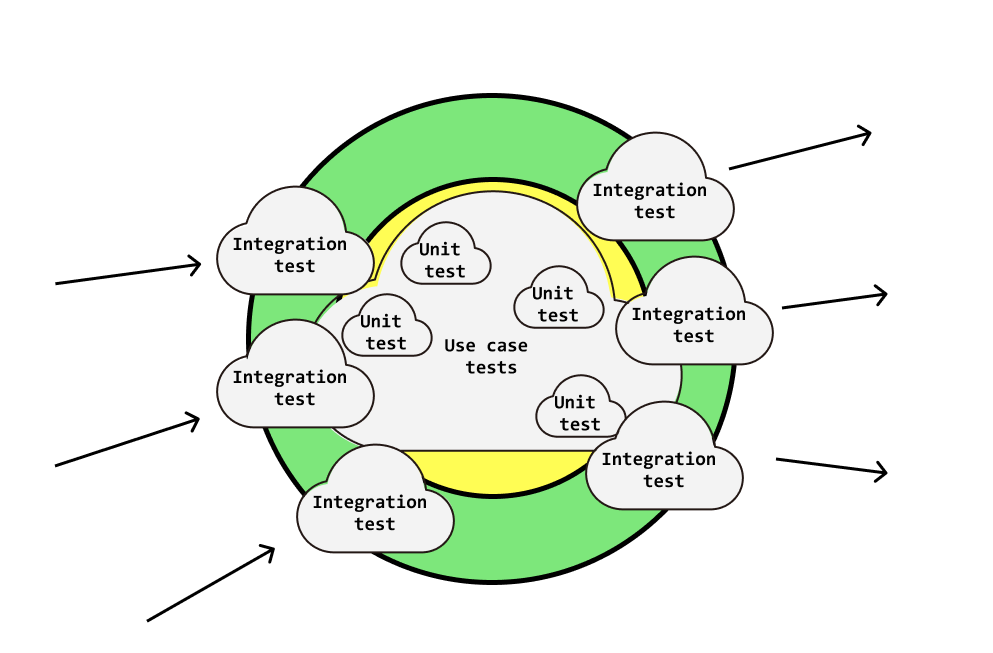
You see? In reality, we want to use a mixture of techniques to cover as much ground as possible.
Further reaading
Not sure where you are on the path? Take the Phases of Craftship quiz — 7 questions, personalized results.
Stay in touch!
Join 20000+ value-creating Software Essentialists getting actionable advice on how to master what matters each week. 🖖
View more in Test-Driven Development