This is page one of a guide on Client-Side Architecture basics.
Why we need a client-side architecture standard
Allow me to paint the picture of why we need a better client-side architecture. To start, let's look at the foundation we're all currently working on top of.
Model-View controller
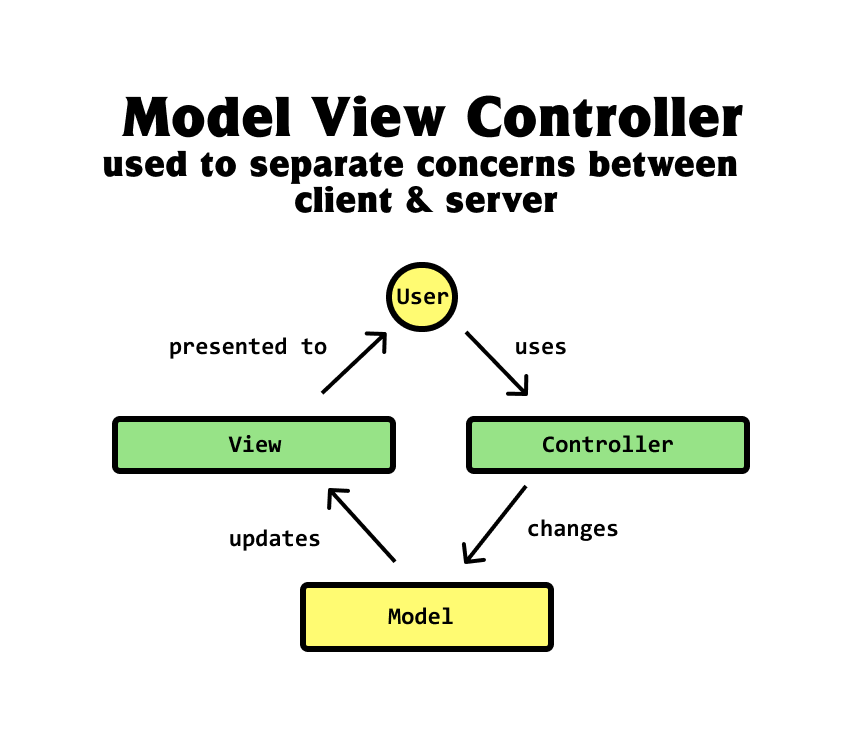
You've probably heard of Model-View-Controller, the architectural pattern that describes how to design apps involving user interfaces.
MVC says that we should split our application into model, view, and controller layers. This is so each layer can focus on their own respective responsibilities.
The model handles data and logic
The view handles presentation
and the controller turns user events into changes to the model
Model-view-controller architectural pattern. Used to separate the concerns between a client-side web app and backend services.
Most full-stack apps are comprised of a client-side portion, utterly separate from backend services. When users ask to make a change from the UI, it makes things happen by interacting with the backend through some API: in MVC, the API is the controller.
This works! And we like it. At least, we must — it's one of the first architectural patterns we teach to new developers learning how to build full-stack apps.
Model-View presenter
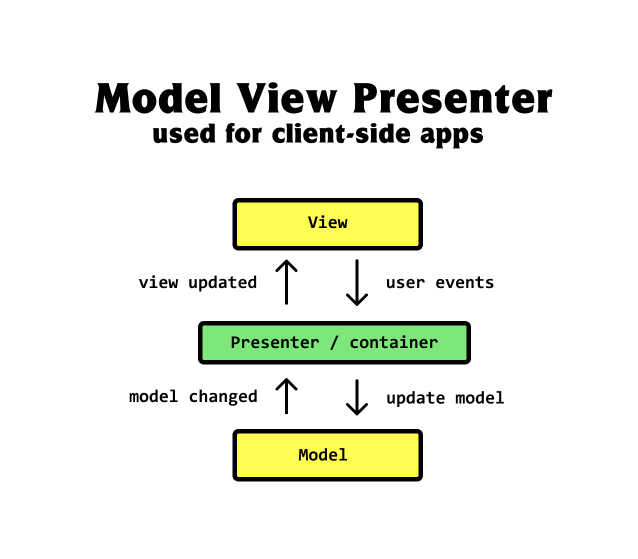
Where Model-View-Controller explained how to separate the concerns of a full-stack web application, Model-View Presenter, a derivation of MVC, told us how to separate the concerns of the client part.
Model-View-Presenter is the architectural pattern typically used within client applications. It's a derivation of the MVC pattern.
In Model-View-Presenter, the view creates user events.
Those user events get turned into updates or changes to the model.
When the model changes, the view is updated with the new data.
It's heartening to realize that every client app uses some form of the model-view presenter pattern.
MVC & MVP are too generic
MVC and MVP are great starters. They give you a good enough understanding of the communication pathways from a 5000-ft view.
Unfortunately, they both suffer from the same problem: being too generic.
In both MVC and MVP, the biggest challenge is that the M is responsible for way too much.
As a result, developers don't know which tools are responsible for which tasks.
In MVC and MVP, the model is ambiguous. This makes matching the correct tool up to the task feel like a puzzle.
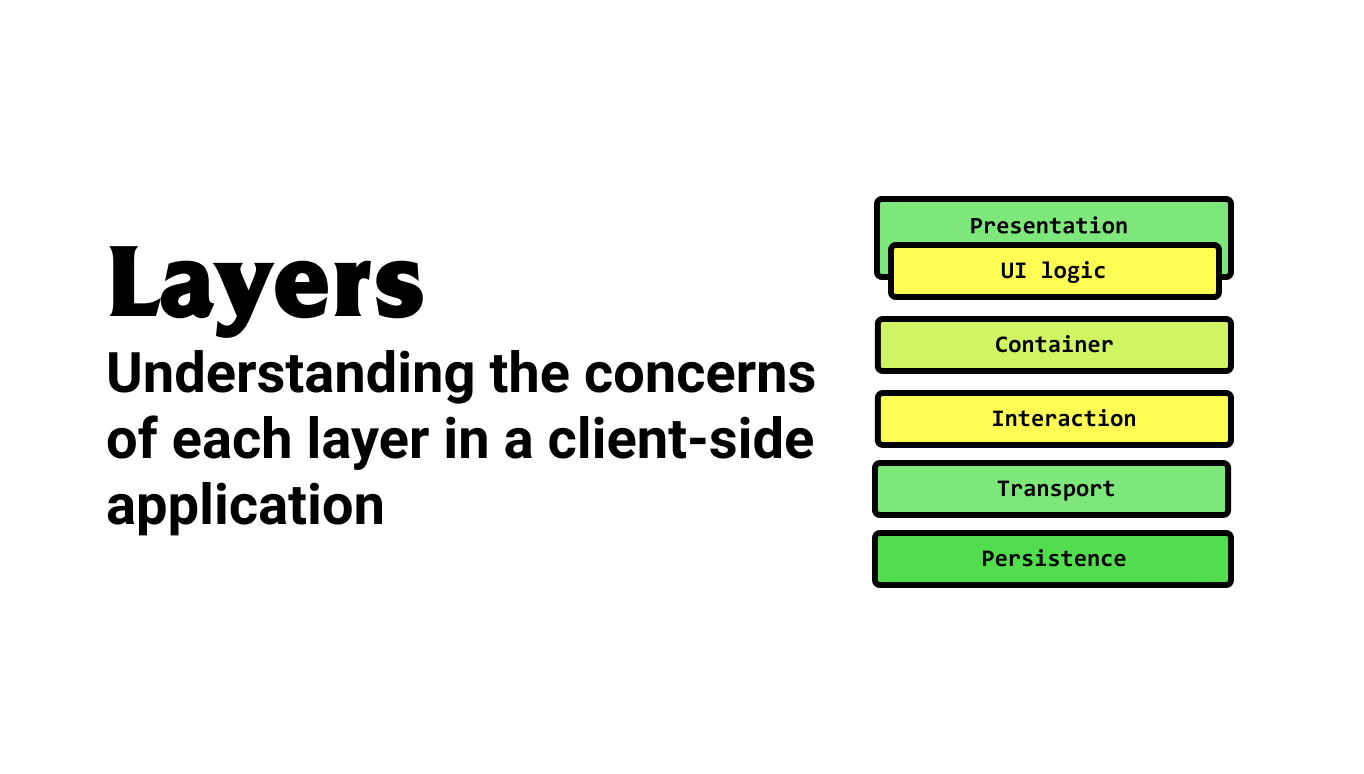
Tasks of the model
In the real world, the model portion in most client-side web apps does a lot.
State management — Most apps need a way to fetch state, update state, and configure reactivity to when state changes, the view can re-render.
Networking & data fetching — The actual data-fetching concern is sometimes conflated as part of the model. The data fetching and networking aspect of an app need to know about backend services, formulate requests, handle responses, and marshal data, but it also needs to signal request metadata (ie: isLoading, error). What about features like optimistic updates? Is that a concern of the model? I think it is.
Model behavior (ie: domain, app, or interaction logic) — Deciding what happens next when a user clicks submit, or wants to interact with something on the page is a form of interaction logic. Sometimes there are rules we need to enforce. They can be simple — like validation before sending off an API call. They can be complicated — like deciding if a chess piece can be dropped on the selected square.
Some call this app logic, which I believe to be sufficient since it describes how our app responds to user events. Alternatively, I call it interaction logic because it explains what happens in response to user interaction.
There's one other kind of logic here, and that's domain logic. Domain logic doesn't normally have anything to do with the application itself. Instead, it originates from an understanding of the domain. For example, while displaying a modal before move a chess piece might be application/interaction logic, enforcing the policy that a knight can only move in an L-shaped fashion is a form of domain logic. That rule originates from understanding the domain of chess where the application-specific logic holds rules about how the user interacts with the app. Usually, domain logic lives behind backend services, and if we break the rules, we can get an error back as a response. Still, sometimes we co-locate it on the client-side, especially for more complex applications.
Authentication & authorization logic (specific type of model behavior) — This is another specific type of model behavior, but it's common enough to mention. Most of the time, authN & authR finds itself being used from within the view layer (show Login screen if not authenticated). Sometimes, it manifests in the application/interaction layer as well, preventing access to specific operations.
Tools used within the model
These are all common challenges to solve. In 2020, the developer toolbox for a React developer looks a little something like this:
React hooks
Redux
Context API
Apollo Client
xState
react-query
and now, recoil
Each of these are capable of addressing a particular piece of the ambiguous model we described, but matching the correct tool to the proper concern can be tricky.
Of course, it's tricky. We don't have a standard language to describe the different concerns. Instead of thinking about the tools right away, I think we need to back up and look at the bigger picture of the problems to be solved.
We need a shared language to talk about client-side architecture
We need a shared language to describe these architectural concepts upon which we either:
Configure a library or a framework to solve
Write the code ourselves for
Most React developers know the implementation-specific terminology like hooks, reducers, context, and props, but architectural concerns are sometimes misunderstood.
Having a shared understanding of what constitutes client-side architecture concerns enables us to:
Have better design conversations
Communicate which concerns are addressed by which tool
Avoid code from concerns creeping too profoundly into another
If we can, as a community, communicate a shared understanding of the concerns that make up the model (and the other parts), I think we can more easily answer questions like this:
Where do we put application logic in a React/Redux app? What about an Apollo Client one? What about a [insert new library/framework here] one?
Should I use container components?
Should I put my GraphQL mutations inside of my component?
Do I need to write tests for Apollo Client? Redux?
What kind of logic should I put in a React hook?
I've got good news for you...
We've already solved this problem
Let's not discredit the software design and architecture research done over the last 30 years.
While the tools and approaches to web development have changed at a miraculous pace, software designprinciples and patterns have remarkably, remained the same.
Knowledge drain: When (domain, trade, scientific) knowledge is lost or forgotten over time.
Let's look at backend development.
How did we solve the ambiguous model problem when building out backend services?
Initially, with MVC on the server, we thought the model could be services, ORMs, or even the database itself. Each of these are part of the model, but they're not the entire model.
According to wikipedia, the model is supposed to represent the data, logic, and any rules of the application.
The clean architecture sheds more light on how to structure your backend in a testable and flexible way. It also helps accommodate for more advanced applications containing business logic.
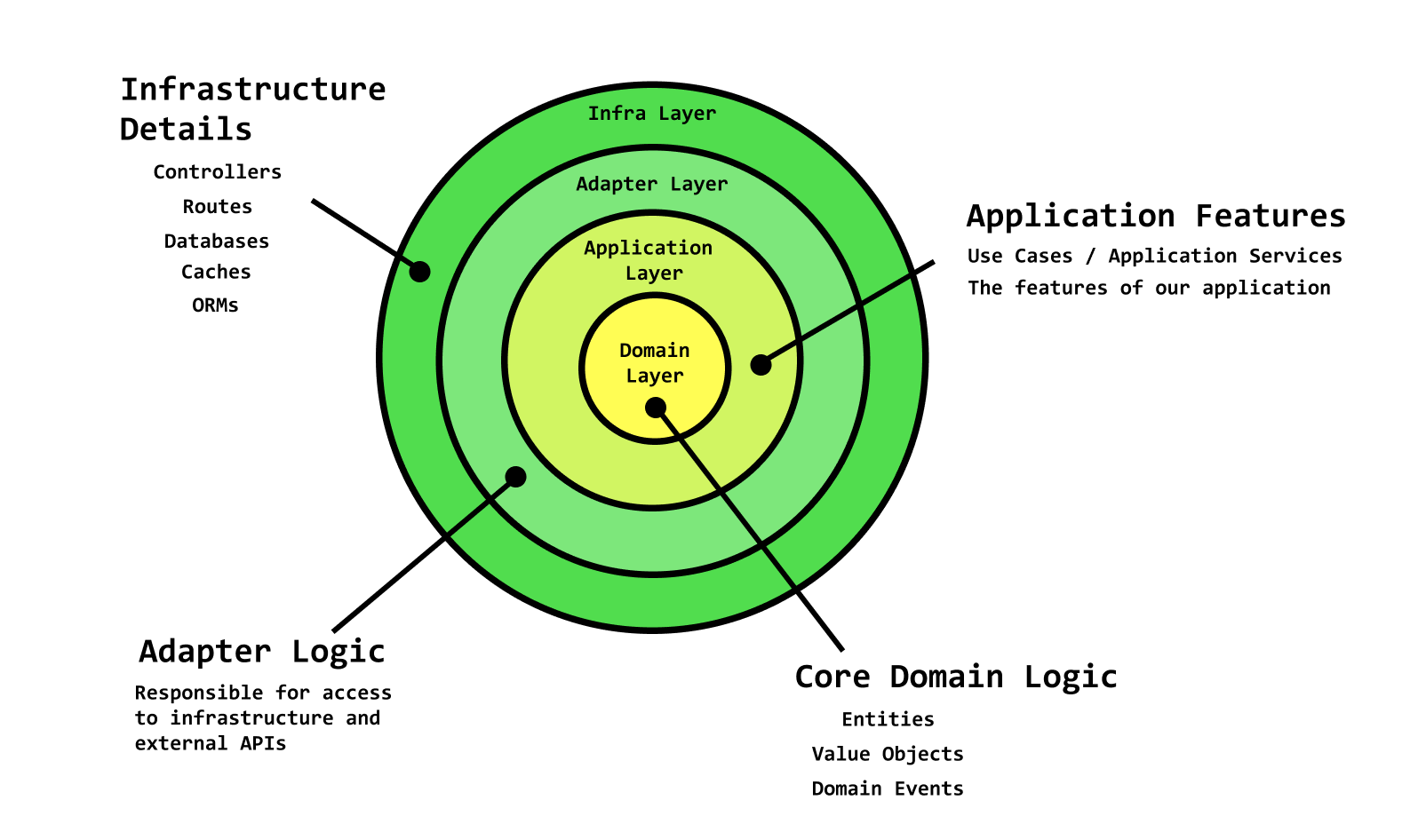
The clean architecture (which has many similar variants — see layered, hexagonal architecture, or ports & adapters) provides specifics as to what the M in the model is.
By splitting the model into infrastructure,application, and domain layers, we exercise the separation of concerns design principle, and we're left with a much easier to reason about architecture.
The middle layers (domain and application) are the purest. It's the code that we, the developers, have to write from scratch. And since our app doesn't do much unless we can hook it up to the real-world using things like web servers, databases, APIs, and caches, the adapter layer provides a flexible way to integrate those infrastructural dependencies into our app, while keeping them distanced from our domain and app layer code.
A layered architecture like this comes at the cost of being more complex than a simple single-tiered one, but let's be honest — sometimes we have to solve some damn hard problems.
A layered architecture has a lot of benefits:
It makes it extremely clear which tools are needed at which layer of the stack.
It keeps concerns separate and enables you to keep your app and domain layer code unit testable.
It allows you to mock out expensive to test things, and swap libraries and frameworks (not that you do that too often — but, in case you ever needed to, you can).
That's hella cool.
Quick question.
Where's our client-side version of this?
Client-side needs — testability, flexibility, and maintainability
Let's back up a bit.
Before we discuss an equivalent client-side architecture, let's talk about our needs first.
We don't want to dogmatically copy the clean architecture.
What are we really looking for when we talk about architecture on the client-side? Why does any of this matter? Why don't we just write all of our code in a single file (actually, some of us do write single file components)? Is architecture about file organization, or is it about something more?
It's about writing testable, flexible, and maintainable code.
Testability
I've noticed that an alarming amount of developers don't write tests for their front-end code.
It could be a conscious decision of choosing not to write tests — which is one thing, but it could also be a lack of education for how to write code so that it can be tested.
I've found that depending on your testing strategy, your needs to separate concerns changes. If you're only going to be writing integration tests, then separation of concerns matters less. If you're going to be writing a lot of unit tests, then mocking is going to be your saving grace, and separation of concerns is paramount.
If you understand the app you're building and the complexity of it, you can kind-of gauge this upfront.
When to write unit tests
+
Unit testing is the preferred approach for testing your client app if there's a heavy amount of interaction/app logic, like a metadata layer in a 3D rendered game, chess game logic, a boating application, or a streaming site like Twitch.
If the accuracy of the most important use cases cannot be verified by merely observing the side effects in the view, then unit tests are the way to go.
When to write integration tests
+
Kent C. Dodds recommends integration tests when 90% of your users' primary use cases can be tested against by observing changes to the view in response to user interaction. In this case, we're talking about basic CRUD apps.
The view is an implementation detail, and it's recommended to not test against implementation details. Testing library provides an excellent suite of tools to run integration tests on React apps through the view without focusing on implementation details.
Flexibility
It's not so often that we need to switch from REST to GraphQL or swap out APIs, but there are a select few cases that we should enable flexibility for.
Swapping out view components — Keeping app logic out of your presentational components allows you to swap out how the component looks from how it works, as painlessly as humanly possible.
Changing model behavior — If your app is the interaction-logic heavy kind of app that needs lots of unit tests, using dependency inversion to mock out API and framework code enables you to run fast tests against the behavior of the model.
Maintainability
Maintainability is our ability to constantly provide value. If we struggle to change code or add new features, maintainability is low.
It's worthy to note that if developer experience is low, there's a chance maintainability is low as well.
Here's an argument to challenge everything I've praised about a clean architecture so far. Looking at it from another point of view, too many layers and too many rules traditionally yields low developer experience for newer developers less familiar with the approach.
This might be why so many new developers prefer to use React over Angular. Angular is actually quite opinionated and forces you towards a particular style of architecture. React lets you do whatever.
There's a balance to be struck here. We want the structure of architecture, but we want the developer experience of knowing what to do and having the freedom to do it however we want.
Design is the balance of conflicting priorities
Office furniture = cost vs. quality
Note-taking = context vs. compression — Tiago Forte
And more relevant to us:
Software design = structure vs. developer experience
I believe that developers who care not only about getting the job done but also getting it done right will push through learning curves.
Next page
II. Principles
Influential design principles that we'll use as the philosophy for our design.
Join 15000+ value-creating Software Essentialists getting actionable advice on how to master what matters each week. 🖖
Get notified
About the author
Khalil Stemmler, Software Essentialist ⚡
I'm Khalil. I turn code-first developers into confident crafters without having to buy, read & digest hundreds of complex programming books. Using Software Essentialism, my philosophy of software design, I coach developers through boredom, impostor syndrome, and a lack of direction to master software design and architecture. Mastery though, is not the end goal. It is merely a step towards your Inward Pull.

.png)
.png)
.png)


.png)

 • Open sourced on
• Open sourced on • Deployed on
• Deployed on