
GraphQL's Greatest Architectural Advantages

Readers that frequent this blog know that I often look for answers to the hard questions in software design and architecture 🧐.
Over the past few years, we've seen companies of all shapes and sizes like Expedia, Nerdwallet, and AirBnb incrementally adopt GraphQL throughout their organizations.
In this article, we'll discuss specific architectural advantages to using GraphQL in your next project or adopting it for an existing one.
We'll talk about:
- Where GraphQL belongs in the modern web application architecture.
- Why infrastructure code shouldn't be our focus on web development.
- The Data Graph: the newest layer in the modern web application stack.
- How the Data Graph unblocks frontend developers and removes the need for them to rely on backend developers.
- How to scale and separate concerns with Apollo Federation.
- How GraphQL and Apollo Federation eliminates the need to do API versioning.
The Hexagonal architecture
Alistair Cockburn's "Hexagonal architecture," says that the inner-most layer of our architecture holds the application and domain layer. Right outside of that layer are the adapters (or ports).
Think of ports as "a way to connect the outside world to the inside world." The outside world is full of technologies that we can use to build our application on top of. Outside, you'll find databases, external APIs, cloud services, and all kinds of other stuff. If we practice dependency inversion, we can safely involve them within our application by defining ports. Ports are abstractions. Contracts. They often appear in the form of interfaces or abstract classes.

Alistair Cockburn's "Hexagonal Architecture".
I believe pretty strongly in this type of architecture because it enables us to:
- Delay the decision on exactly which type of web server, database, transactional email provider, or caching technology until it's absolutely necessary to decide. We can always use an in-memory implementation of the port for initial development efforts.
- It also prioritizes writing code that can be tested by using Dependency Injection. This helps to minimize concrete dependencies that can make code untestable.
- Lastly, it adjusts our focus to the application and domain-specific stuff. The stuff we can't just buy off the shelf or download.
Infrastructure Components
GraphQL servers and HTTP servers are examples of infrastructure components.
Infrastructure components: Fundemental components that comprise the foundation of a web application. Based on the clean (or hexagonal) architecture, databases, web servers, and caches are outer layer infrastructure components.
We call infrastructural components infrastructure because they are foundational to the application we build on top of it. It's within this foundation- this skeleton, that we write our rich, domain-specific applications. The infrastructure is simply the driver.
Another primary characteristic about infrastructure components is that they aren't the focus of our development efforts for a project.
Infrastructure components are tools trusted by the industry, and we only need to configure them to make them work.
Configuration of a GraphQL API involves:
- Installing GraphQL
- Exposing a server endpoint
- Designing a schema
- Connecting resolvers to data sources
This is work, but it's not the focus of our work on a project.
If a certain piece of infrastructure technology is trusted by the industry, there's a good chance that we can expedite our development efforts by letting that tool do its job instead of developing our own infrastructure component.
Consider databases. They're infrastructural too.
For example, a Postgres database is one of several databases we could use for a new project. Imagine the pushback you'd get from your team if you tried to convince them it was essential for the project to write your own database from scratch.
The scenario seems silly when we think about how it applies to choosing a persistence technology, but choosing your web application API style (transport/client-server technology) is a similar situation.
It was last year (2019) when I realized that APIs cut deeper into the stack than we think. APIs touch the edges of our front-end frameworks' data stores, and they touch the contracts (see Design by Contract) of our backend services.
If this sounds a bit virtual, that's because it kinda is. At Apollo GraphQL, we call that virtual layer the Data Graph. And Apollo builds tools that improves developer productivity working with it.
The Data Graph
I first heard the idea of a Data Graph from Matt DeBergalis, CTO of Apollo GraphQL, at GraphQL Summit 2019.
I highly recommend Matt's talk at GraphQL Summit 2019 where he introduces the concept of the Data Graph.
The Data Graph is virtual layer that sits in between our client-side application and a GraphQL server. It holds the entirety of an organization's data and provides the language for how to fetch and mutate state within the entire organization.
The Data Graph is a declarative, self-documenting, organization-wide GraphQL API.
To me, the Data Graph is a previously missing layer in the modern application stack.

Basic full stack Apollo Client + Server application stack.
The Data Graph brings the remote state closer to client-side local state
Three challenges all front end frameworks need to solve are data storage, change detection, and data flow.
React developers typically need to patch on Redux or Context, and write lots of boilerplate code to satisfy these requirements.
When Apollo released Apollo Client with apollo-link-state, they enabled React developers to meet all three needs satisfied with a lot less code.
Apollo-link-state (now baked directly into Apollo Client 2 and 3), made it possible for developers to write queries that address both remote state and local state at the exact same time. Remote state (sitting on a server) feels much closer.
Take this query to fetch a particular dog by its breed, for example:
const GET_DOG = gql`
query GetDogByBreed($breed: String!) {
dog(breed: $breed) {
images {
url
id
isLiked @client # signal to resolve locally
}
}
}
`;In this query primarily intended to fetch remote resources, we can use the @client directive to refer to properties we want to fetch from our local cache based on a client-side schema. Very cool that this can be done in the same request. Think about the amount of spread and Object.assign()s operations we normally do in a Redux environment.
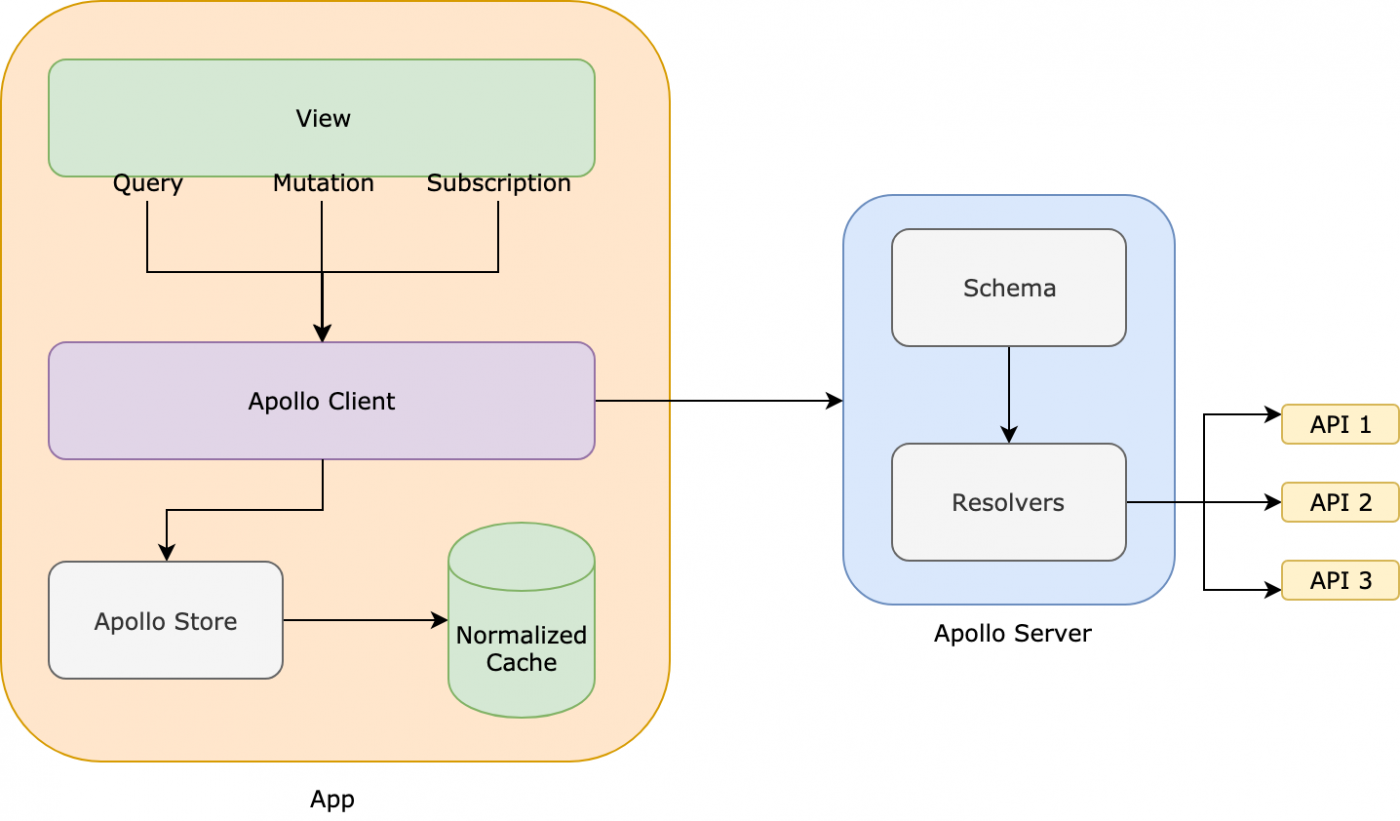
Depiction of the the simplified data-fetching architecture where the view is any front-end framework - Source nerdwallet.
The Data Graph, with Apollo Server and Client on both ends of the connection, simplifies fetch logic, error logic, retry logic, pagination, caching, optimistic UI, and various other types of boilerplate data-plumbing code.

The Data Graph stretches from client to server and has an answer for the most common infrastructural problems when fetching data and mutating state in modern web applications.
In order communicate with a backend service through GraphQL, Apollo Client exposes several client-side methods that, when invoked, converts the operation into the appropriate API to cross the Data Graph.
On the Apollo Server end, those API calls pass control off to resolvers responsible for fetching data using ORMs, raw SQL, caches, other RESTful APIs or anything else you can think of. For mutations, a resolver can simply pass control to an application layer use case.
By making the use cases the focal point of your application, switching from REST to GraphQL (or supporting both) is a breeze.
GraphQL is self documenting
One bummer in mainting a RESTful API is keeping documentation up to date and adequate.
There are two things that can change for a RESTful API.
- The route + method combination
- The request shape + parameters
A route + method combination example is that it's quite easy for someone to move the operation that creates a user from POST /users to POST /users/new. An API change like this would likely go unnoticed, break all clients of the API, and be virtually impossible for the API client to detect what the combination was changed to.
A request shape + parameters example is one where the POST request to /users/new used to only require an email and a password, but now, it requires a username property as well. The only way for an API client to understand what to do to remedy the request would be to check the error response (hopefully, error messages are descriptive otherwise this too would be impossible).
If you consider introspection adequate documentation, then GraphQL is self-documenting and impossible for your API documentation to get out of sync.
Using GraphQL Playground, one can browse all of the capabilities of a GraphQL endpoint.
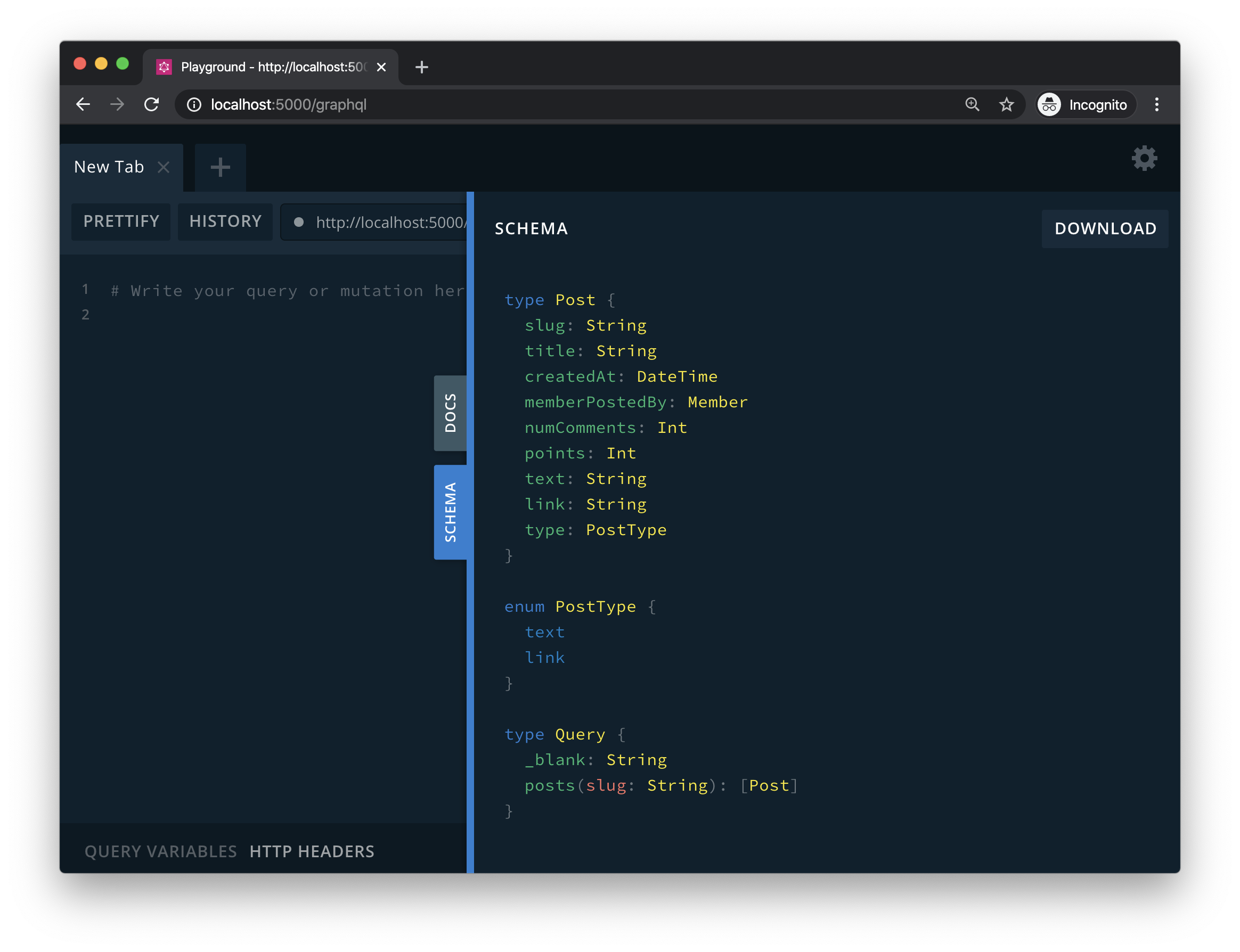
GraphQL Playground's GraphQL explorer can display all of the capabilities of a GraphQL endpoint due to the ability to execute introspection queries.
In REST-land, I've only seen APIs shipped with this amount of metadata built using Swagger. This is a very powerful feature that not only makes the code the single source of truth for documentation, but opens up the surface area of ways we can perform codegen to automate the creation of TypeScript types, client-side libraries, or service-to-service communication.
Because the GraphQL language is ubiquitous and standardized, humans and machines will have an easier time understanding how to integrate and work with it.
Scaling and Separation of Concerns
Principled GraphQL states that,
"Your company should have one unified graph, instead of multiple graphs created by each team."
The emergence of multiple graphs within a company is something that will start to happen as more and more teams catch on to GraphQL.
Using Apollo Federation, each service team can build and manage their own GraphQL service from their bounded context, register it to an Apollo Gateway, distributing GraphQL operations across the entire enterprise.

Apollo Federation lets us grow and expose a single Data Graph composed of several GraphQL endpoints.
In Federation, you can compose schemas and resolve fields from other services/bounded contexts. When a request comes in, those fields get resolved from the appropriate service 👍.
Solving this problem is not uncommon for any organization of substantial size.
A single endpoint
The Open-Closed Principle from the SOLID principles states that:
"A component/system/class should be open for extension, but closed for modification".
Architecturally, because GraphQL only exposes a single endpoint to the client, it satisfies this principle.
All of the complexities of how fields are being resolved are hidden from the client, and all it needs to focus on is how to build on top of the GraphQL server.

An illustration that depicts the evolution of an organization's Data Graph over time.
Empowers frontend developers
The Data Graph reduces front-end developers' reliance on backend developers to develop new endpoints for new use cases.
Small UI changes where we rip out components or realize that we've misjudged our data requirements and actually need a few more fields for components, happen quite often. Because this happens so often, and because REST is so rigid, it creates this dependency on the back-end team to make changes to the REST APIs any time we need adjustments.
Depending on the team structure, each of the following questions signal potential to reduce developer productivity and create a reliance on the backend team.
- Is the team fragmented? Are front-end developers strictly front-end, or are they also allowed to work on the other side of the stack?
- Are your backend developers remote?
- Are your backend developers in the office?
GraphQL removes the need to manage API versions
Principled GraphQL also has a strong opinion on versioning. It states that:
"The schema should be built incrementally based on actual requirements and evolve smoothly over time."
This means that the team should practice agile schema development by iteratively making changes instead of chunking changes in huge releases.
That's great, and all, but I live in the real world just like you. I know that that's not always possible, at least not without the proper tooling.
The Apollo platform has a feature called schema validation that lets you test every change against live production traffic and shows you when breaking changes are proposed, enabling teams to converse on how to continue.
Neat!
Getting started: For more information on how to use Schema Validation, check out the docs, Evans Hauser's talk, and sign up for a free Teams trial.
Conclusion
- Within the modern web application architecture, GraphQL and RESTful Web Servers are infrastructure components.
- Infrastructure components are fundemental components that comprise the foundation of a domain-specific web application we code within them.
- Infrastructure components aren't the focus of most web development projects, so we should aim to spend most of our time on application and domain layer code.
- The Data Graph is a declarative, self-documenting, organization-wide GraphQL API, brings remote state closer to the client-side, and can be scaled using Apollo Federation.
- Front-end developers are empowered to create their own data-fetching use cases without the reliance on backend developers by using the Data Graph.
- GraphQL removes the need to manage API versions and Apollo's Graph Manager can faciliate production schema validation.
There are a lot of scenarios where GraphQL makes sense architecturally.
I'm still in the process of trying everything out for myself. I'll be updating this article periodically as I get my hands dirty, so check back in a little while.
Not sure where you are on the path? Take the Phases of Craftship quiz — 7 questions, personalized results.
Stay in touch!
Join 20000+ value-creating Software Essentialists getting actionable advice on how to master what matters each week. 🖖
View more in GraphQL